GPT-4 ve ChatGPT ile Uygulama Geliştirmek

Hayal edin, bilgisayarlarla insanlar gibi doğal bir şekilde iletişim kurabileceğiniz bir dünya. OpenAI’in GPT modelleri, büyük miktardaki veriyle eğitilerek insan benzeri metinleri üretme yeteneğine sahip yapay zeka modelleridir. GPT-4 ve ChatGPT gibi modeller, sadece sesli asistanların ötesine geçerek, ihtiyaçlarımızı anlayan ve kişiselleştirilmiş uygulamalar oluşturmamıza olanak tanır. Bu yapay zeka modelleri, geniş bir yelpazede yenilikçi çözümler sunabilir, örneğin öğrenme stillerine uyum sağlayabilen eğitim araçları veya gelişen ihtiyaçlara adapte olan müşteri destek sistemleri. GPT-4 ve ChatGPT’nin temel prensiplerini anlamak, geleceğin dil modeli destekli uygulamalarını geliştirme yolunda önemli bir adımdır.
GPT-4 ve ChatGPT, transformer adı verilen belirli bir derin öğrenme algoritmasına dayanıyor. Transformerlar adeta metin okuma makineleri gibidir. Bir cümlenin veya metin bloğunun farklı kısımlarına dikkat ederek bağlamını anlar ve tutarlı bir yanıt üretirler. Aynı zamanda cümle içindeki kelime sırasını ve bağlamını anlayabilirler. Bu özellikleri, dil çevirisi, soru cevaplama ve metin üretimi gibi görevlerde son derece etkili olmalarını sağlar. Aşağıdaki şekil, bu terimler arasındaki ilişkileri göstermektedir
Gördüğünüz gibi, bir Geniş Dil Modeli (GLM), verilen bir giriş ipucuna dayanarak bir cevap üretmek için sıradan bir şekilde sonraki kelimeleri (veya öğeleri) tahmin ederek ilerler. Çoğu durumda, modelin çıktısı ilgili ve tamamen göreviniz için kullanılabilir olsa da, dil modellerini uygulamalarınızda kullanırken dikkatli olmak önemlidir çünkü tutarsız cevaplar verebilirler. Bu tür cevaplar genellikle yanıltıcı hayal ürünleri olarak adlandırılır. Yapay Zeka yanıltıcı hayal ürünleri, AI’nın size yanlış veya hayali gerçeklere atıfta bulunan, kendinden emin yanıtlar verdiğinde ortaya çıkar. Bu, GPT’ye güvenen kullanıcılar için tehlikeli olabilir. Modelin cevabını tekrar kontrol etmeniz ve eleştirel bir şekilde incelemeniz gereklidir.
Aşağıdaki örneği düşünün. Modelden basit bir hesaplama yapmasını istiyoruz: 2 + 2. Beklendiği gibi, 4 cevabını veriyor. Yani doğru. Harika! Daha karmaşık bir hesaplama yapması için ona şu soruyu soruyoruz: 3,695 × 123,548. Doğru cevap 456,509,860 olsa da, model büyük bir özgüvenle yanlış bir cevap veriyor, Aşağıdaki şekilde gördüğünüz gibi. Ve bu cevabı kontrol etmesi ve tekrar hesaplaması istendiğinde hala yanlış bir cevap veriyor.

GPT-4 ve ChatGPT, basit tamamlama özelliğinin ötesine geçen gelişmiş dil modelleridir. Bu konu, iki yönteme odaklanıyor: Plug-inler ve ince ayar.
GPT’nin bazı sınırlamaları vardır, örneğin hesaplamalarda. Bu nedenle OpenAI, dış uygulamalarla entegre edilebilen plug-in hizmeti sunar. Bu plug-inler, modelin dış dünyayla etkileşimini artırabilir, gerçek zamanlı bilgi alabilir, eylemler gerçekleştirebilir ve matematik hesaplamalarını yapabilir.
Konu aynı zamanda ince ayar tekniklerini de ele alıyor. İnce ayar, mevcut bir modeli belirli bir görev için daha hassas hale getirmek için kullanılır. Yeni veri üzerinde modeli tekrar eğiterek bu özelleştirme sağlanır. Bu sayede, model belirli bir görevde daha iyi performans sergileyebilir.
Sonuç olarak, GPT-4 ve ChatGPT, dil anlama ve üretme yeteneklerini ileri seviyeye taşıyarak insan benzeri etkileşimlerin kapılarını açıyor.
Bu bölüm, GPT-4 ve ChatGPT API’larını detaylı bir şekilde inceliyor. Bu bölümün amacı, bu API’ların kullanımını sağlam bir şekilde anlamanızı sağlamak, böylece bunları Python uygulamalarınıza etkili bir şekilde entegre edebilirsiniz. Bu bölümün sonunda, bu API’ları kullanma konusunda iyi donanımlı olacak ve kendi geliştirme projelerinizde bu güçlü yeteneklerini kullanabileceksiniz.
OpenAI Playground’a bir girişle başlayacağız. Bu, kod yazmadan önce modelleri daha iyi anlamanıza olanak tanır. Ardından, OpenAI Python kütüphanesine bakacağız. Bu, giriş bilgilerini ve basit bir “Merhaba Dünya” örneğini içerir. Daha sonra API’lara istek oluşturma ve gönderme sürecini ele alacağız. Ayrıca, API yanıtlarını nasıl yöneteceğimize de bakacağız. Bu, bu API’lar tarafından döndürülen verileri nasıl yorumlayacağınızı bildiğinizden emin olmanızı sağlayacak. Ayrıca, bu bölüm, güvenlik en iyi uygulamaları ve maliyet yönetimi gibi konuları da ele alacak.
OpenAI, çeşitli görevler için tasarlanmış birkaç model sunmaktadır ve her birinin kendi fiyatlandırması bulunmaktadır. İlerleyen sayfalarda, mevcut modellerin detaylı bir karşılaştırmasını ve hangi modelleri kullanmanız gerektiği konusunda ipuçları bulacaksınız. Bir modelin tasarlandığı amaç — metin tamamlama, sohbet veya düzenleme gibi — API’sını nasıl kullanmanız gerektiğini etkiler. Örneğin, ChatGPT ve GPT-4'ün arkasındaki modeller sohbet tabanlıdır ve sohbet uç noktasını kullanır.
İlk bölümde “ipucu” kavramı tanıtıldı. İpucular, OpenAI API’sine özgü değil, tüm LLM’lerin giriş noktasıdır. Basitçe söylemek gerekirse, ipuçları, modele gönderdiğiniz giriş metnidir ve modelin belirli bir görevi nasıl gerçekleştireceğine dair talimatları içerir. ChatGPT ve GPT-4 modelleri için ipuçları bir sohbet formatına sahiptir, giriş ve çıkış mesajları bir listede saklanır. Bu bölümde bu ipucu formatının detaylarını inceleyeceğiz.
Tokenlar kelimeler veya kelimelerin parçalarıdır. Yaklaşık olarak 100 token, İngilizce bir metinde yaklaşık 75 kelimeye eşdeğerdir. OpenAI modellerine yapılan istekler, kullanılan token sayısına göre fiyatlandırılır: yani bir API çağrısının maliyeti, hem giriş metni hem de çıkış metni uzunluğuna bağlıdır.
OpenAI Playground ile GPT Modellerini Denemek OpenAI tarafından sunulan çeşitli dil modellerini kod yazmadan doğrudan test etmek için mükemmel bir yol, OpenAI Playground’u kullanmaktır. Bu web tabanlı platform, belirli görevler için OpenAI tarafından sağlanan farklı LLM’leri hızlı bir şekilde denemenize imkan tanır. Playground, size ipuçları yazma, model seçme ve üretilen çıktıyı kolayca görme olanağı sunar. İşte Playground’a nasıl erişileceği:
- OpenAI ana sayfasına gidin ve Geliştiriciler bölümüne tıklayın, ardından Genel Bakış’a göz atın.
- Eğer zaten bir hesabınız varsa ve oturum açmamışsanız, ekranın sağ üst köşesindeki Giriş yap seçeneğine tıklayın. Eğer OpenAI ile henüz bir hesabınız yoksa, Playground’u kullanmak ve OpenAI’nin çoğu özelliğinden yararlanmak için bir hesap oluşturmanız gerekecek. Bu durumda, ekranın sağ üst köşesindeki Kaydol seçeneğine tıklayın. Lütfen unutmayın ki, Playground ve API kullanımı ücretli olduğundan, bir ödeme yöntemi sağlamanız gerekecektir.
- Oturum açtıktan sonra, web sayfasının sol üst köşesinde Playground’a katılma bağlantısını göreceksiniz. Bu bağlantıya tıklayarak aşağıdaki şekilde benzer bir ekran göreceksiniz.
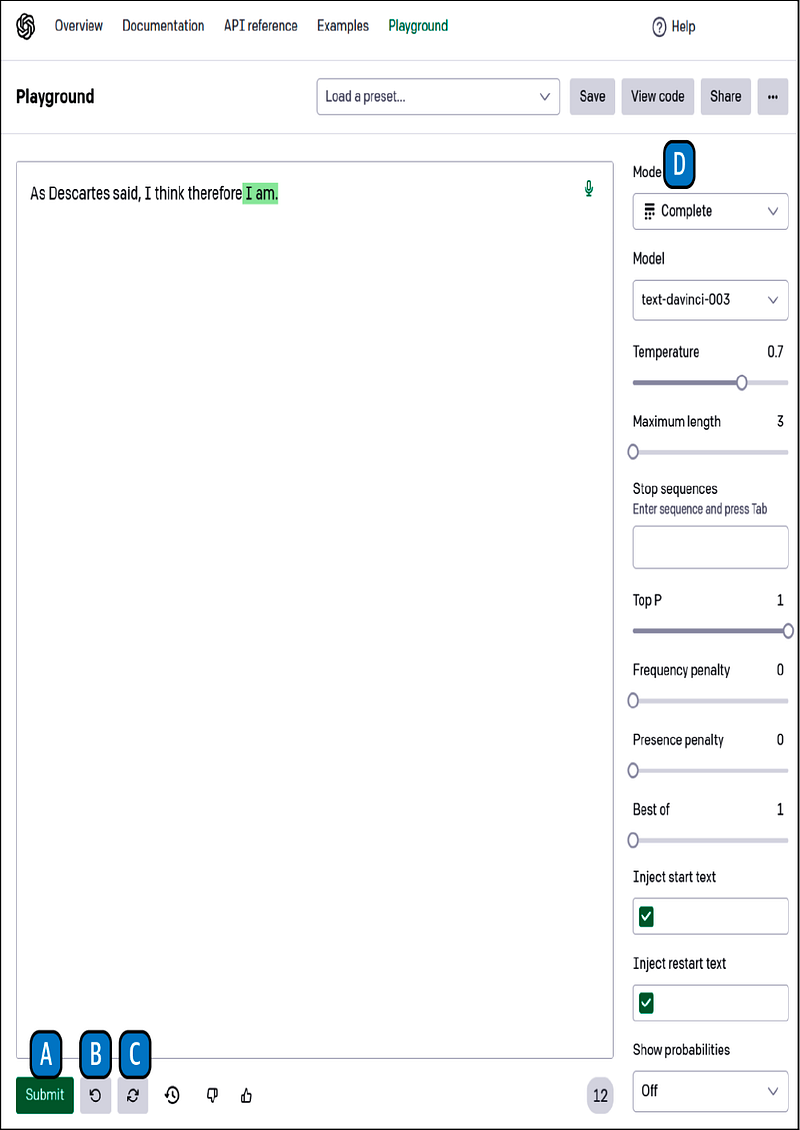
Daha önce gösterildiği gibi, dil modeli, Playground’ın varsayılan modunda kullanıcının giriş ipucunu sorunsuz bir şekilde tamamlamayı amaçlar. Yukarıdaki şekil, Playground’ı Sohbet modunda kullanmanın bir örneğini gösterir. Ekranın sol tarafında Sistem bölmesi yer alır [E ile etiketlenmiştir]. Burada sohbet sisteminin nasıl davranması gerektiğini tanımlayabilirsiniz. Örneğin, şekilde ondan kedilere düşkün yardımcı bir karakter olmasını istedik. Aynı zamanda sadece kedilerden konuşmasını ve kısa cevaplar vermesini istedik. Bu parametrelerin belirlenmesinden kaynaklanan diyalog ekranın ortasında görüntülenir.
Eğer sistemle diyaloga devam etmek istiyorsanız, “Mesaj ekle” [F] düğmesine tıklayın, mesajınızı girin ve Gönder [G] düğmesine tıklayın. Ayrıca modeli sağ tarafta tanımlamak da mümkündür [H]; burada GPT-4'ü kullanıyoruz. Lütfen tüm modellerin tüm modlarda kullanılamayabileceğine dikkat edin. Örneğin, sadece GPT-4 ve GPT-3.5 Turbo, Sohbet modunda kullanılabilir modeller arasındadır.
Ara yüzü ayrıntılı bir şekilde incelediğinizde, birçok ayrıntılı seçenek ve özellikle karşılaşacaksınız. Şimdi ise işin daha keyifli ve ilgi çekici kısmına geçelim.
Başlangıç: OpenAI Python Kütüphanesi
Bu bölümde, küçük bir Python betiği içinde API anahtarlarını nasıl kullanacağımıza odaklanacağız ve bu OpenAI API ile ilk testimizi gerçekleştireceğiz. OpenAI, GPT-4 ve ChatGPT’yi bir hizmet olarak sağlar. Bu, kullanıcıların modellerin koduna doğrudan erişemeyeceği ve modelleri kendi sunucularında çalıştıramayacakları anlamına gelir. Ancak OpenAI, modellerin dağıtımını ve çalıştırılmasını yönetir ve kullanıcılar bir hesap ve gizli bir anahtarları olduğu sürece bu modellere çağrı yapabilirler. Aşağıdaki adımları tamamlamadan önce, OpenAI web sayfasına giriş yaptığınızdan emin olun.
OpenAI, hizmetlerini kullanabilmeniz için bir API anahtarına sahip olmanızı gerektirir. Bu anahtarın iki temel amacı bulunmaktadır:
- API yöntemlerini çağırma hakkı verir.
- API çağrılarınızı hesap faturalandırması için hesabınıza bağlar.
OpenAI hizmetlerini uygulamanızdan çağırabilmek için bu anahtara sahip olmanız gerekmektedir. Anahtarı elde etmek için OpenAI platform sayfasına gidin. Sağ üst köşede, hesap adınıza tıklayın ve ardından Aşağıda gösterildiği gibi “API Anahtarlarını Görüntüle” seçeneğine tıklayın.
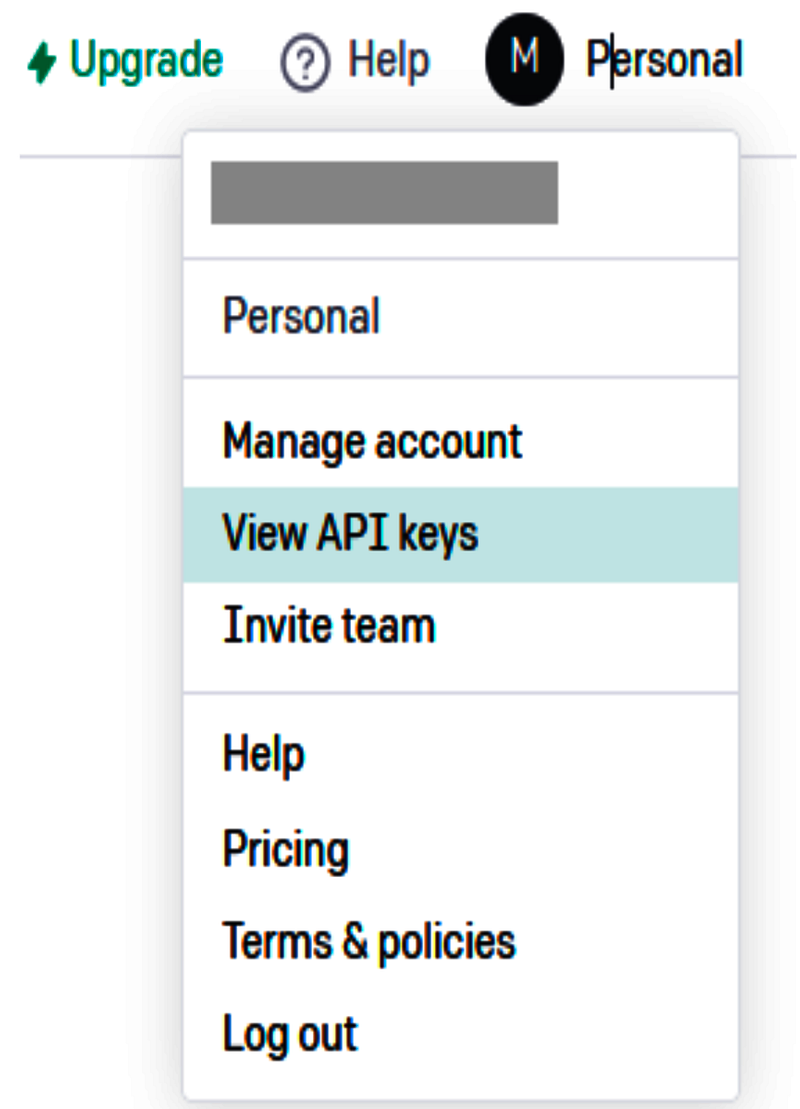
“API anahtarları” sayfasındayken, “Yeni gizli anahtar oluştur” seçeneğine tıklayın ve anahtarınızın bir kopyasını alın. Bu anahtar, sk- ile başlayan uzun karakter dizisi şeklindedir.
Bu anahtarı güvende ve güvenli bir şekilde saklayın, çünkü doğrudan hesabınıza bağlıdır ve çalınan bir anahtar istenmeyen maliyetlere neden olabilir.
Anahtarınıza sahip olduktan sonra, yapacağınız en iyi şey, onu bir çevre değişkeni olarak dışa aktarmaktır. Bu, uygulamanızın anahtara doğrudan kodunuzda yazmadan erişmesine olanak tanır. İşte bunu nasıl yapacağınız:
Linux yada Mac İçin:
// ortam değişkenini değiştir
export OPENAI_API_KEY=API_KEYINIZ
// ortam değişkenini kontrol et
echo $OPENAI_API_KEYWindows İçin:
// ortam değişkenini değiştir
set OPENAI_API_KEY=API_KEYINIZ
// ortam değişkenini kontrol et
echo %OPENAI_API_KEY%Tebrikler artık OpenAI API’sini kullanabilmemiz için herşey hazır!
“Merhaba Dünya” Örneği
Bu bölüm, OpenAI Python kütüphanesiyle ilk kod satırlarını göstermektedir.
OpenAI’nin hizmetlerini nasıl sağladığını anlamak için klasik bir “Merhaba Dünya” örneği ile başlayacağız.
Python kütüphanesini pip ile yükleyin:
pip install openaiGerekli kütüphaneleri kodumuza dahil edelim:
from dotenv import load_dotenv
load_dotenv()
import os
import openaiDaha sonra OpenAI kütüphanesi ile yeni bir sohbet akışı oluşturalım:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Hello World!"}
]
)Son olarak ise gelen yanıtı ekrana yazdıralım.
print(response['choices'][0]['message']['content'])Birde kodumuzu tamamen ele alalım:
from dotenv import load_dotenv
load_dotenv()
import os
import openai
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Merhaba dünya!"}
]
)
print(response['choices'][0]['message']['content'])Elde edeceğimiz çıktı
Merhaba! Size nasıl yardımcı olabilirim?Şeklinde olacaktır.
Tebrikler! OpenAI kütüphanesi kullanarak ilk kodunuzu yazdınız!
Metin tamamlama ve sohbet tamamlama arasında önemli bir fark bulunmaktadır: her ikisi de metin üretir, ancak sohbet tamamlama konuşmalar için optimize edilmiştir. Aşağıdaki kod parçasında gördüğünüz gibi, openai.ChatCompletion uç noktasıyla ana fark, ipucu formatındadır. Sohbet tabanlı modellerin konuşma formatında olmaları gerekmektedir; tamamlama için ise tek bir ipucu yeterlidir:
import openai
response = openai.Completion.create(
model="text-davinci-003", prompt="Merhaba dünya"
)
print(response["choices"][0]["text"])Bu kod örneği, aşağıdaki gibi bir tamamlama çıktısı üretecektir:
\n\nSizinle tanıştığıma memnun oldum.Ancak diğer türlü bir completion oluştursaydınız vereceği cevap
Zaman karmaşıklığının ne anlama geldiğini açıklayın.Şeklinde olurdu ve anlamlı bir cevap alamazdınız.
Güvenlik ve Gizlilik: Dikkat!
Bu yazıyı yazdığımız sırada, OpenAI modellere giden verilerin yeniden eğitim için kullanılmayacağını ve bunun için tercih yapmadığını iddia ediyor. Ancak girdileriniz, izleme ve kullanım uyum kontrol amaçları için 30 gün boyunca saklanır. Bu, OpenAI çalışanlarının yanı sıra özel üçüncü taraf uygulamaların API verilerinize erişimi olabileceği anlamına gelir.
Uyarı
Kişisel bilgiler veya şifre gibi hassas verileri OpenAI uç noktaları aracılığıyla asla göndermeyin. En güncel bilgiler için OpenAI’nin veri kullanım politikasını kontrol etmenizi öneririz, çünkü bu değişebilir. Uluslararası bir kullanıcıysanız, kişisel bilgilerinizin ve girdi olarak gönderdiğiniz verilerin yerinizden Amerika Birleşik Devletleri’ndeki OpenAI tesislerine ve sunucularına aktarılabileceğini unutmayın. Bu, uygulama oluşturmanız üzerinde bazı hukuki etkilere sahip olabilir.
Diğer OpenAI API’ları ve İşlevselliği
OpenAI hesabınız, metin tamamlamanın ötesinde farklı işlevlere erişim sağlar. Bu bölümde keşfetmek için birkaç bu işlevlerden bazılarını seçtik, ancak tüm API olanaklarına detaylı bir bakış isterseniz, OpenAI’nin API referans sayfasına göz atabilirsiniz.
Gömmeler (Embedds)
Bir model, matematiksel işlevlere dayandığı için bilgiyi işlemek için sayısal girişlere ihtiyaç duyar. Ancak kelimeler ve belirteçler gibi birçok öğe özünde sayısal değildir. Bu durumu aşmak için gömme (embeddings), bu kavramları sayısal vektörlere dönüştürür. Gömme, bilgisayarların bu kavramlar arasındaki ilişkileri daha verimli bir şekilde işlemelerine olanak tanır, çünkü bu kavramları sayısal olarak temsil eder. Bazı durumlarda, gömme (embeddings)lere erişmek faydalı olabilir ve OpenAI, bir metni sayı vektörüne dönüştürebilen bir model sunar. Gömme (embeddings) uç noktası, geliştiricilerin bir giriş metnin sayı vektörü temsilini elde etmelerine olanak tanır. Bu sayı vektör temsili daha sonra diğer makine öğrenimi modellerine ve doğal dil işleme algoritmalarına giriş olarak kullanılabilir.

Moderasyon Modeli
OpenAI Modellerini kullanırken, OpenAI kullanım politikalarında belirtilen kurallara uymalısınız.
OpenAI, bu kurallara uygunluğu kontrol etmek için bir moderasyon modeli sağlar.
Bu moderasyon modeli, kullanıcı girişlerini temel alarak uygulamada içerik denetimi yapmanıza yardımcı olabilir.
Aşağıdaki kategorilerde içeriği kontrol etme yeteneği sunar:
- Nefret:
- Irk, cinsiyet, etnik köken, din, milliyet, cinsel yönelim, engellilik veya kast temelinde gruplara karşı nefret içeren içerikler.
2. Nefret/Tehdit:
- Hedeflenen gruplara yönelik şiddet veya ciddi zarar içeren nefret dolu içerikler.
3. Kendine Zarar:
- Kendine zarar verme eylemlerini tanımlayan veya tasvir eden içerikler, buna intihar, kesme ve yeme bozuklukları dahildir.
4. Şiddet:
- Şiddeti övme veya diğerlerinin acı çekmesini veya aşağılanmasını kutlayan içerikler.
5. Grafik Şiddet:
- Grafik ayrıntılarla ölüm, şiddet veya ciddi fiziksel zararı tasvir eden şiddet içeren içerikler.
Bu moderasyon modeli sayesinde kullanıcıların gönderdiği içerikleri uygunluk açısından değerlendirebilir ve gerektiğinde filtreleyebilirsiniz.
Moderasyon modeli için uç nokta, openai.Moderation.create’dir ve yalnızca iki parametre bulunur: model ve giriş metni. İki tür içerik moderasyon modeli bulunmaktadır. Varsayılan olanı text-moderation-latest’tir ve zaman içinde otomatik olarak güncellenir, böylece her zaman en doğru modeli kullanmış olursunuz. Diğer model ise text-moderation-stable’dır. OpenAI, bu modeli güncellemeden önce sizi bilgilendirecektir.
import openai
response = openai.Moderation.create(
model="text-moderation-latest",
input="I want to kill my neighbor.",
)Bu isteğe verilen yanıt şu şekilde olacaktır:
{
"id": "modr-7AftIJg7L5jqGIsbc7NutObH4j0Ig",
"model": "text-moderation-004",
"results": [
{
"categories": {
"hate": false,
"hate/threatening": false,
"self-harm": false,
"sexual": false,
"sexual/minors": false,
"violence": true,
"violence/graphic": false,
},
"category_scores": {
"hate": 0.0400671623647213,
"hate/threatening": 3.6716878639,
"self-harm": 1.3143378509994363e,
"sexual": 5.508050548996835e-07,
"sexual/minors": 1.1862029225540,
"violence": 0.9461417198181152,
"violence/graphic": 1.4636998457
},
"flagged": true,
}
]
}Yazılım Mimarisi Tasarım İlkeleri
OpenAI API’si ile sıkıca bağlı olmayan bir şekilde uygulamanızı oluşturmanızı öneririz. OpenAI hizmeti değişebilir ve OpenAI’nin API yönetimine karşı gücünüz yoktur. En iyi uygulama, bir API değişikliğinin uygulamanızı tamamen yeniden yazmanızı gerektirmemesini sağlamaktır. Bu genellikle mimari tasarım kalıplarını takip ederek gerçekleştirilir.
Örneğin, standart bir web uygulama mimarisi alttaki şekilde görüldüğü gibi olabilir. Burada, OpenAI API’si harici bir hizmet olarak kabul edilir ve uygulamanın arka ucu aracılığıyla erişilir.

Proje 1: Bir Haber Üretici Çözümü Oluşturma
ChatGPT ve GPT-4 gibi Büyük Dil Modelleri (LLM’ler), metin üretimi için özel olarak tasarlanmıştır. ChatGPT ve GPT-4'ü çeşitli metin üretimi kullanım durumları için kullanabilirsiniz:
- E-posta
- Sözleşmeler veya resmi belgeler
- Yaratıcı yazılar
- Adım adım eylem planları
- Beyin fırtınası
- Reklamlar
- İş teklifi açıklamaları
Bu kullanım alanlarının sınırları yoktur. Bu projede, bir liste verildiğinde haber makaleleri üretebilen bir araç oluşturmaya karar verdik. Makalelerin uzunluğu, tonu ve stili, hedef medyaya ve hedef kitleye uyacak şekilde seçilebilir. Şimdi, openai kütüphanesinin tipik importlarını ve ChatGPT modeline çağrı yaparken kullanılacak bir sarma işlevini içeren bir işlev ile başlayalım:
def ask_chatgpt(messages):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return (response['choices'][0]['message']['content'])Şimdi, daha iyi sonuçlar için ayrıntılı olarak ele alınacak olan tekniklerden birini kullanarak bir öneri oluşturalım: yapay zeka modeline bir rol atamak ve görev açıklamasında mümkün olduğunca kesin olmak. Bu durumda, ona gazeteciler için bir asistan olmasını söylüyoruz:
prompt_role='You are an assistant for journalists. \
Your task is to write articles, based on the FACTS that are given to you. \
You should respect the instructions: the TONE, the LENGTH, and the STYLE'Son olarak ana fonksiyonumuzu belirtiyoruz:
def assist_journalist(facts: List[str], tone: str, length_words: int, style: str):
facts = ", ".join(facts)
prompt = f'{prompt_role}\nFACTS: {facts}\nTONE: {tone}\nLENGTH: {length_words} words\nSTYLE: {style}'
return ask_chatgpt([{"role": "user", "content": prompt}])Ve şimdi de yanıtı ekrana yazdırıp test edelim:
print(assist_journalist(['The sky is blue', 'The grass is green'], 'informal', 100, 'blogpost'))Ardından bu kodu çalıştırdığımızda sanki bir haber muhabiri asistanı gibi bizim girdigimiz prompta yanıt verir.
Bunu sadece bu şekilde kısıtlamak yerine web sitelerinizde veya uygulamalarınızda bir çok sitilde kullanabilirsiniz.
Proje 2: YouTube Videolarını Özetleme
Büyük Dil Modelleri’nin (LLM’ler) metni özetleme konusunda başarılı olduğu kanıtlanmıştır. Çoğu durumda, temel fikirleri çıkarmayı başarırlar ve özgün girdiyi yeniden ifade ederek üretilen özetin akıcı ve net hissetmesini sağlarlar. Metin özetleme birçok durumda kullanışlı olabilir:
- Medya takibi: Bilgi aşırı yükleme olmadan hızlı bir genel bakış alın.
- Trend izleme: Teknoloji haberlerinin özetlerini oluşturun veya akademik makaleleri gruplayarak kullanışlı özetler elde edin.
- Müşteri destek: Müşterilerinizin genel bilgilerle ezilmediği belgelerin özetlerini oluşturun.
- E-posta göz gezdirme: En önemli bilgilerin görünmesini sağlayın ve e-posta aşırı yüklemesini engelleyin.
Bu örnekte YouTube videolarını özetleyeceğiz. Şaşırmış olabilirsiniz: Videoları ChatGPT veya GPT-4 modellerine nasıl besleyebiliriz? İşte buradaki hile, bu görevi iki ayrı adım olarak düşünmektir:
- Videodan transkripti çıkarın.
- Adım 1'deki transkripti özetleyin. Bir YouTube videosunun transkriptine çok kolay bir şekilde erişebilirsiniz. İzlemeyi seçtiğiniz videonun altında, aşağıdaki görselde gösterildiği gibi kullanılabilir işlemler bulacaksınız. “…” seçeneğine tıklayın ve ardından “Transkripti göster” seçeneğini seçin.
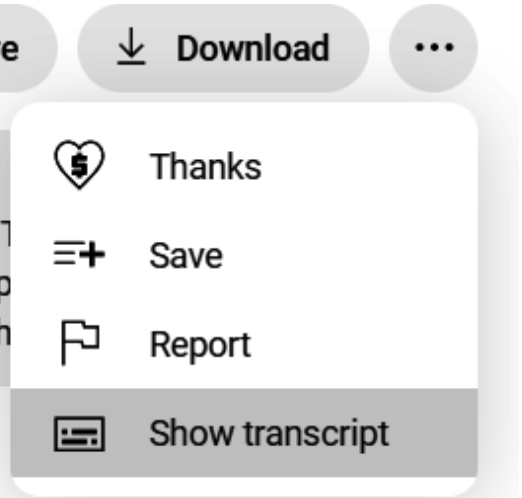
Bir metin kutusu görünecek ve içinde video transkripti bulunacaktır; bu, aşağıdaki şekilde gösterildiği gibi görünmelidir. Bu kutu ayrıca zaman damgalarını açıp kapamanıza izin verir.
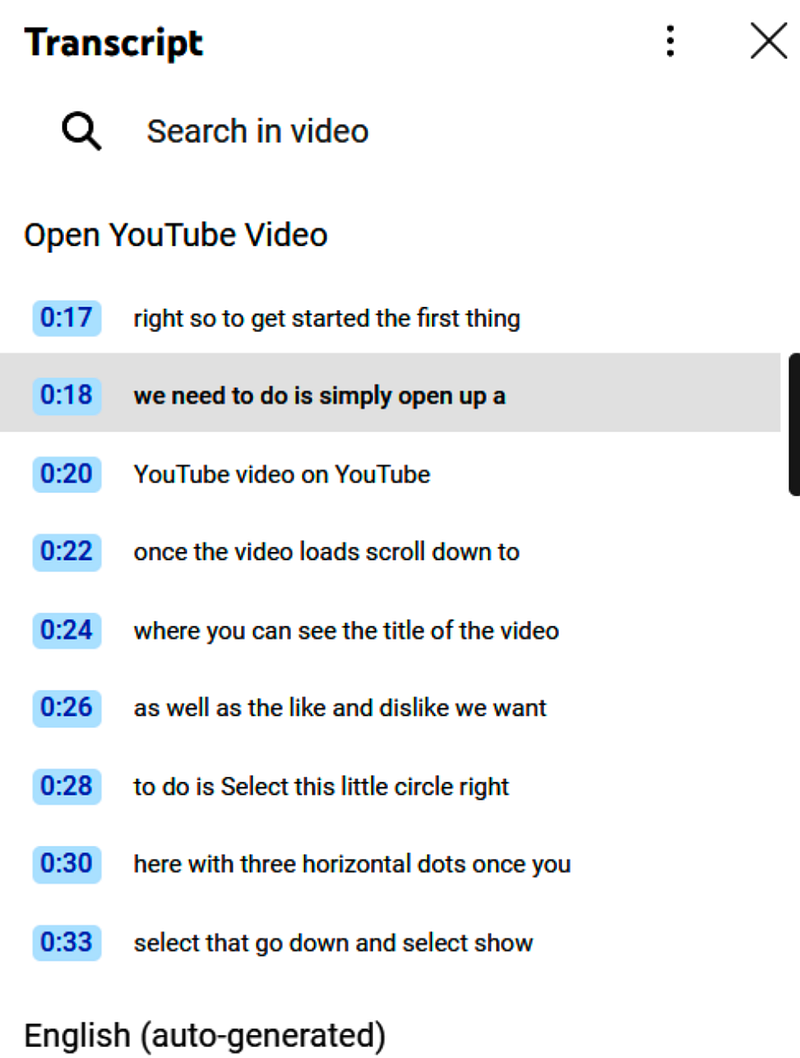
Eğer bunu sadece bir kez, tek bir video için yapmayı planlıyorsanız, YouTube sayfasında görünen transkripti kopyalayıp yapıştırabilirsiniz. Ancak birden fazla video için yapmayı düşünüyorsanız, OpenAI tarafından sağlanan API gibi daha otomatik bir çözüm kullanmanız gerekebilir.
YouTube videolarıyla programatik olarak etkileşimde bulunmanıza olanak tanıyan bir API’den bahsediyoruz.
Bu API’yi ya doğrudan kullanabilirsiniz, bu durumda altyazı kaynaklarını kullanırsınız, ya da youtube-transcript-api gibi üçüncü taraf bir kütüphane veya Captions Grabber gibi bir web aracını kullanabilirsiniz. Transkripti elde ettikten sonra, özetleme işlemi için bir OpenAI modelini çağırmanız gerekecek.
Bu iş için GPT-3.5 Turbo modelini kullanıyoruz. Bu model bu basit görev için çok iyi çalışır ve bu yazının yazıldığı tarihe göre en az maliyetli seçenektir. Aşağıdaki kod örneği, modelden bir transkriptin özetini oluşturmasını istemektedir:
from dotenv import load_dotenv
load_dotenv()
import openai
# Read the transcript from the file
with open("../files/transcript.txt", "r") as f:
transcript = f.read()
# Call the openai ChatCompletion endpoint, with the ChatGPT model
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize the following text"},
{"role": "assistant", "content": "Yes."},
{"role": "user", "content": transcript},
],
)
print(response["choices"][0]["message"]["content"])Unutmayın ki eğer videonuz uzunsa, transkript izin verilen maksimum 4096 token için çok uzun olacaktır. Bu durumda, maksimum sınırı geçmek için örneğin aşağıdaki şekilde gösterilen adımları takip etmeniz gerekecektir.
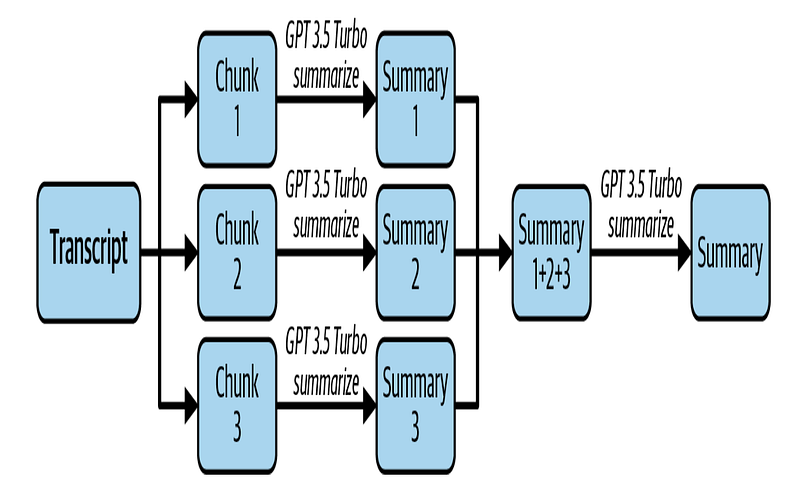
Bu proje, basit özetleme özelliklerini uygulamanıza entegre etmenin, çok az kod satırıyla bile nasıl değer katabileceğini göstermiştir. Kendi kullanım durumunuza uygulayarak oldukça faydalı bir uygulama elde edebilirsiniz. Aynı prensibe dayalı bazı alternatif özellikler de oluşturabilirsiniz: anahtar kelime çıkarımı, başlık oluşturma, duygu analizi ve daha fazlası.
Proje 3: Whisper ile Sesten Metne Dönüşüm
Kodumuz oldukça basit. Herşeyden önce aşağıdaki komutu konsolunuzda çalıştırarak whisper-openai kütüphanesini kuralım.
pip install openai-whisperBir model yükleyebilir ve bir ses dosyasının yolunu girdi olarak alan ve transkript metnini döndüren bir yöntem oluşturabiliriz:
import whisper
model = whisper.load_model("base")
def transcribe(file):
print(file)
transcription = model.transcribe(file)
return transcription["text"]Bu asistanın prensibi, OpenAI’nin API’sinin kullanıcının girdisiyle kullanılacak olmasıdır ve modelin çıktısı, geliştirici için bir gösterge olarak veya kullanıcı için bir çıktı olarak kullanılacaktır, aşağıdaki gibi gösterildiği gibi:
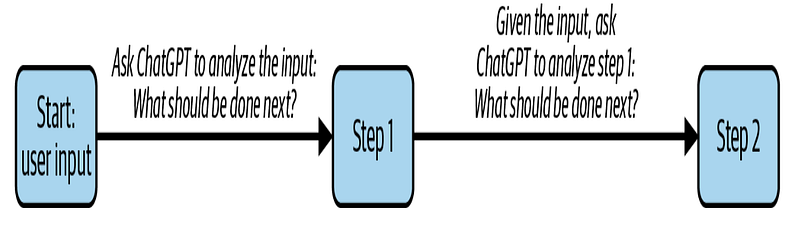
Şimdi yukarıdaki şemayı adım adım inceleyelim. İlk olarak, ChatGPT kullanıcının girdisinin cevaplanması gereken bir soru olduğunu tespit eder: Adım 1 SORU’dur. Kullanıcının girdisinin bir soru olduğunu bildikten sonra, ChatGPT’den bunu cevaplamasını istiyoruz. Adım 2, sonucu kullanıcıya vermek olacaktır. Bu sürecin amacı, sistemimizin kullanıcının niyetini bilmesi ve buna uygun davranmasıdır. Eğer niyet, belirli bir eylemi gerçekleştirmekse, bunu tespit edebiliriz ve gerçekten gerçekleştirebiliriz.
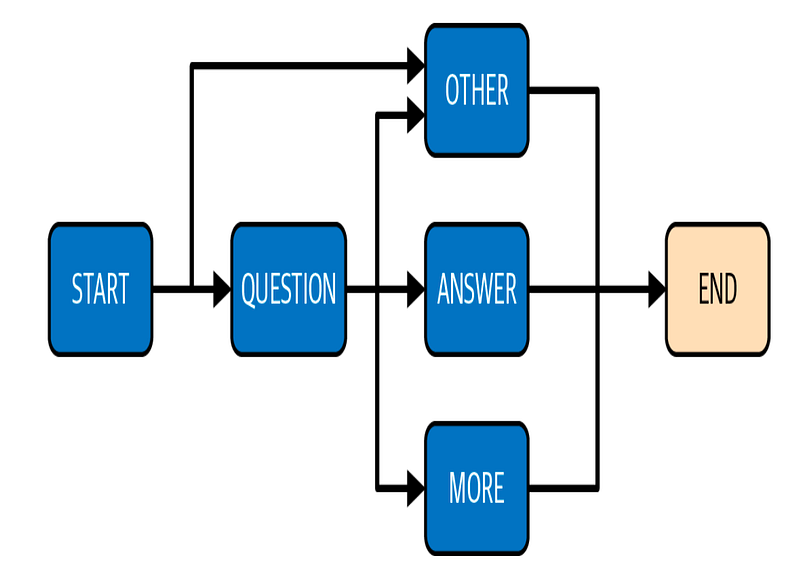
Görüldüğü gibi, bu bir durum makinesidir. Bir durum makinesi, belirli bir sonlu durum kümesine sahip sistemleri temsil etmek için kullanılır. Durumlar arası geçişler, belirli girdilere veya koşullara dayanmaktadır.
Örneğin, asistanımızın soruları yanıtlamasını istiyorsak, dört durum belirleriz:
SORU: Kullanıcının bir soru sorduğu tespit edilmiştir.
CEVAP: Soruyu yanıtlamaya hazırız.
DAHA FAZLA: Daha fazla bilgiye ihtiyaç duyuyoruz.
DİĞER: Tartışmaya devam etmek istemiyoruz (soruyu yanıtlayamıyoruz).
Bu durumlar aşağıdaki şemada gösterilmiştir.
Gelişmiş GPT-4 ve ChatGPT Teknikleri
Artık LLM’lerin temellerini ve OpenAI API’sini anladınız, yeteneklerinizi bir üst seviyeye taımanın zamanı geldi. Bu bölüm, ChatGPT ve GPT-4'ün gerçek potansiyelini kullanmanıza olanak sağlayacak güçlü stratejileri ele alıyor. Prompt mühendisliğinden, sıfır vuruşlu öğrenmeye, az vuruşlu öğrenmeye ve özel görevler için modelleri ince ayarlamaya kadar bu bölüm, hayal edebileceğiniz herhangi bir uygulamayı oluşturmak için ihtiyacınız olan tüm bilgiyi sunacak.
Prompt Engineering
Prompt mühendisliğine dalmeden önce, bu bölüm bunu yoğun bir şekilde kullanacak olan sohbet modelinin tamamlama işlevini kısaca gözden geçirelim. Kodu daha kompakt hale getirmek için işlevi aşağıdaki gibi tanımlarız:
from dotenv import load_dotenv
load_dotenv()
import openai
def chat_completion(prompt, model="gpt-4", temperature=0):
res = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature,
)
print(res["choices"][0]["message"]["content"])Bu işlev, bir başlatıcı alır ve tamamlama sonucunu terminalde görüntüler. Model ve sıcaklık (temperature) iki isteğe bağlı özelliktir ve sırasıyla varsayılan olarak GPT-4 ve 0 olarak ayarlanmıştır.
Prompt mühendisliğini göstermek için “Descartes’ın dediği gibi, düşünüyorum o halde” örnek metnine geri döneceğiz. Bu girdi GPT-4'e iletilirse, modelin cümlenin sonunu en olası belirtecileri ekleyerek tamamlaması doğaldır.
chat_completion("Give me a suggestion for the main course for today's lunch.")Prompt mühendisliği, istenilen sonuçları mümkün olduğunca programlı bir şekilde elde etmek için LLM’ler için en iyi uygulamaları geliştirmeye odaklanan bir ortaya çıkan disiplindir. Bir yapay zeka mühendisi olarak, uygulamalarınız için işlenebilir sonuçlar elde etmek için yapay zekayla nasıl etkileşimde bulunmanız gerektiğini, doğru soruları nasıl sormanız gerektiğini ve kaliteli başlatıcıları nasıl yazmanız gerektiğini bilmelisiniz; hepsi bu bölümde ele alacağımız konulardır.
Ayrıca, prompt mühendisliğinin OpenAI API kullanım maliyetini etkileyebileceğini belirtmek önemlidir. API’yi kullanmak için ödeyeceğiniz miktar, OpenAI’ye gönderdiğiniz ve aldığınız belirteçlerin sayısıyla orantılıdır. Daha önce de belirtildiği gibi, faturalarınızda hoş olmayan sürprizlerle karşılaşmamak için max_token parametresini kullanmanız şiddetle önerilir.
Ayrıca, temperature, top_p ve max_token gibi parametreleri openai yöntemlerinde kullanabileceğinizi göz önünde bulundurmanız gerektiğini unutmayın, çünkü aynı başlatıcıyı kullanarak önemli ölçüde farklı sonuçlar alabilirsiniz.
Etkili Promplar Tasarlamak
Birçok görev promplar aracılığıyla gerçekleştirilebilir. Bu görevler özetleme, metin sınıflandırma, duygu analizi ve soru-cevap gibi şeyleri içerir. Bu görevlerin hepsinde, başlatıcıda üç unsurun tanımlandığı yaygındır: bir rol, bir bağlam ve bir görev, aşağıdaki görselde tasvir edildiği gibi. Bu üç unsura her zaman ihtiyaç duyulmaz ve sıraları değiştirilebilir, ancak başlatıcınız iyi kurulmuş ve unsurları iyi tanımlanmışsa, iyi sonuçlar elde etmelisiniz. Bu üç unsur kullanıldığında bile, karmaşık görevler için sıfır-shot öğrenimi, az-shot öğrenimi ve ince ayarlama gibi daha gelişmiş teknikleri kullanmanız gerekebilir. Bu gelişmiş teknikler, bu bölümün ilerleyen kısımlarında ele alınacaktır.

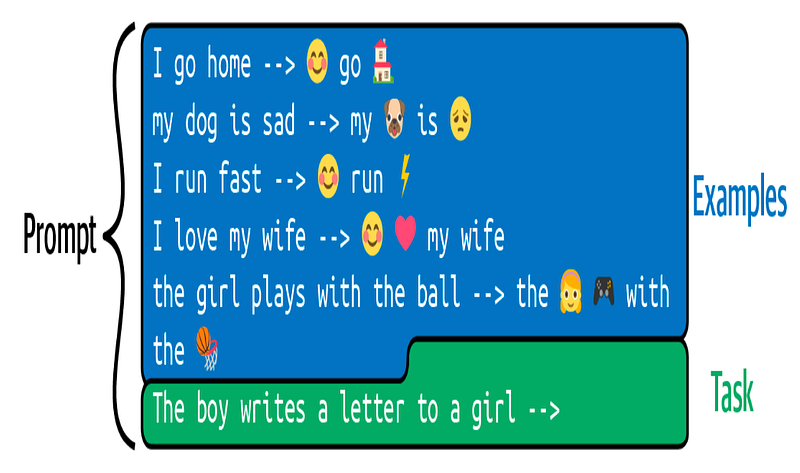
Few-Shot Öğrenimini Uygulamak
“Language Models are Few-Shot Learners” makalesinde Brown ve diğerleri tarafından tanıtılan az shot öğrenimi, LLM’nin sadece birkaç örnekle bile genelleme yapma yeteneğini ifade eder. Az shot öğrenimi ile, modelin istenen çıktı formatını işlemesi için birkaç örnek verirsiniz, bu örnekler alttaki şekilde gösterildiği gibi.
OpenAI API ile Fein Ayarlama
OpenAI API ile bir LLM modelini fine-tuning yapmak için bu bölüm size rehberlik eder. Verilerinizi nasıl hazırlayacağınızı, veri kümesini nasıl yükleyeceğinizi ve API kullanarak fine-tuned model oluşturacağınızı açıklayacağız.
Verilerinizi Hazırlama
Bir LLM modelini güncellemek için örneklerle dolu bir veri kümesi sağlamak gereklidir. Veri kümesi, her bir satırın promptlar ve tamamlamalar çiftine karşılık geldiği bir JSONL dosyası formatında olmalıdır:
{"prompt": "<prompt text>", "completion": "<completion>"}
{"prompt": "<prompt text>", "completion": "<completion>"}
{"prompt": "<prompt text>", "completion": "<completion>"}JSONL dosyası, her satırın bir JSON nesnesini temsil ettiği bir metin dosyasıdır. Büyük miktarda veriyi verimli bir şekilde depolamak için kullanılabilir. OpenAI, bu eğitim dosyasını oluşturmanıza yardımcı olan bir araç sağlar. Bu araç, çeşitli dosya formatlarını (CSV, TSV, XLSX, JSON veya JSONL) giriş olarak alabilir ve yalnızca bir prompt ve tamamlama sütunu/anahtarı içermeleri gerekmektedir. Ardından eğitim için hazır bir JSONL dosyası çıktısı verir. Bu araç ayrıca verinizin kalitesini iyileştirmek için doğrular ve öneriler sunar.
Bu aracı terminalinizde aşağıdaki kod satırını kullanarak çalıştırın:
openai tools fine_tunes.create_finetune_datasetUygulama, sonuç dosyasını iyileştirmek için bir dizi öneride bulunacaktır; bu önerileri kabul edebilirsiniz veya reddedebilirsiniz. Ayrıca, tüm önerileri otomatik olarak kabul eden -q seçeneğini belirtebilirsiniz.
Not
Bu komutu çalıştırabilmek için eğer bilgisayarınızda kurulu değil ise openai kütüphanesini pip install openai komutu ile kurmalısınız.
Yeterli veriye sahipseniz, araç veriyi eğitim ve doğrulama setlerine bölmek gerekip gerekmediğini soracaktır. Bu önerilen bir uygulamadır. Algoritma, ince ayar sırasında modelin parametrelerini değiştirmek için eğitim verisini kullanacaktır. Doğrulama seti, parametreleri güncellemek için kullanılmamış bir veri kümesi üzerinde modelin performansını ölçebilir.
LLM Yeteneklerini LangChain Çerçevesi ve Eklentileri ile Geliştirmek
Bu bölüm, LangChain çerçevesinin ve GPT-4 eklentilerinin dünyasını keşfediyor. LangChain’in farklı dil modelleriyle etkileşimi nasıl sağladığına ve eklentilerin GPT-4'ün yeteneklerini genişletmedeki önemine bakacağız. Bu ileri düzey bilgi, LLM’lere dayalı sofistike ve son teknoloji uygulamalar geliştirmek için temel oluşturacaktır.
LangChain’i kurmak, pip install langchain komutu ile hızlı ve kolaydır.
LangChain’in temel işlevleri modüllere ayrılmıştır, aşağıda gösterildiği gibi:

Modeller
Modeller modülü, farklı LLM’lerle etkileşimde bulunmanıza olanak sağlayan LangChain tarafından sağlanan standart bir arabirimdir. Bu çerçeve, OpenAI, Hugging Face, Cohere, GPT4All gibi çeşitli sağlayıcıların farklı model türü entegrasyonlarını destekler.
Promptlar
Promptlar, LLM’leri programlamak için yeni bir standart haline geliyor. Promptlar modülü, prompt yönetimi için birçok araç içerir.
İndeksler
Bu modül, LLM’leri verilerinizle birleştirmenizi sağlar.
Zincirler
Bu modülle, LangChain, birden fazla model veya promptu birleştiren bir dizi çağrı oluşturmanıza olanak sağlayan Zincir arabirimini sunar.
Ajanlar
Ajanlar modülü, Ajan arabirimini tanıtır. Bir ajan, kullanıcı girdisini işleyebilir, kararlar alabilir ve bir görevi yerine getirmek için uygun araçları seçebilir. İteratif olarak çalışır, bir çözüme ulaşana kadar adım adım işlem yapar.
Bellek
Bellek modülü, zincir veya ajan çağrıları arasında durumu devam ettirmenizi sağlar. Varsayılan olarak, zincirler ve ajanlar durumsuzdur, yani gelen her isteği bağımsız olarak işlerler, LLM’ler gibi.
Dinamik Promptlar
LangChain’in nasıl çalıştığını size en kolay göstermenin yolu, size basit bir komut dosyası sunmaktır. Bu örnekte, OpenAI ve LangChain, basit bir metin tamamlama işlemi yapmak için kullanılır:
from langchain.models import OpenAIApi
from langchain.chains import Chain
# LangChain ile OpenAI modelini entegre ediyoruz
openai_model = OpenAIApi(api_key="YOUR_OPENAI_API_KEY")
# Zincir oluşturuyoruz ve OpenAI modelini ekliyoruz
chain = Chain()
chain.add(openai_model)
# Kullanıcının girdisi
user_input = "Bir gün ormanda yürürken"
# Zinciri çalıştırıyoruz ve tamamlanan metni alıyoruz
completed_text = chain(user_input)
print("Tamamlanan Metin:", completed_text)Agents and Tools
Ajanlar ve Araçlar, LangChain çerçevesinin temel özelliklerinden biridir. Bu modül, kullanıcı girdisini işleyebilen, kararlar alabilen ve bir görevi yerine getirmek için uygun araçları seçebilen bir bileşen olan “Ajan” arayüzünü tanıtır. Ajanlar, iteratif bir şekilde çalışır, çözüme ulaşana kadar adım adım işlem yaparlar.
Araçlar, ajanların kullanabileceği işlevler, hizmetler ve modüller olarak düşünülebilir. Ajanlar, araçları kullanarak belirli görevleri yerine getirebilirler. Bu modül, LangChain’in daha karmaşık ve sofistike uygulamalar geliştirmenize yardımcı olacak bir yapı taşıdır.

Bellek
Bazı uygulamalarda, önceki etkileşimleri hem kısa hem de uzun vadeli olarak hatırlamak son derece önemlidir. LangChain ile, hafızayı yönetmek için zincir ve ajanlara durumları eklemek oldukça kolaydır. Bir sohbet botu oluşturmak, bu yeteneğin en yaygın örneğidir.
Bu yeteneği, ConversationChain kullanarak hızla gerçekleştirebilirsiniz; aslında, birkaç satır kod ile bir dil modelini bir sohbet aracına dönüştürebilirsiniz.
from langchain.models import OpenAIModel
from langchain.agents import SimpleAgent
from langchain.tools import SimpleTools
# OpenAI API anahtarınızı buraya ekleyin
openai_api_key = "YOUR_OPENAI_API_KEY"
# OpenAI modelini oluşturun
openai_model = OpenAIModel(api_key=openai_api_key, model_id="gpt-3.5-turbo")
# Basit bir ajan oluşturun
agent = SimpleAgent()
# Basit araçlar oluşturun
tools = SimpleTools()
# Zinciri oluşturun
chain = agent.chain(openai_model) | tools
# Kullanıcı girişi
user_input = "Merhaba, LangChain ile çalışmak gerçekten kolay mı?"
# Zinciri çalıştırın
response = chain.run(user_input)
# Cevabı yazdırın
print("LangChain Cevabı:", response)GPT-4 Eklentileri
Dil modelleri, GPT-4 dahil, çeşitli görevlerde yardımcı olduklarını kanıtlamış olsalar da, bazı içsel sınırlamalara sahiptirler. Örneğin, bu modeller yalnızca eğitildikleri veri üzerinden öğrenebilirler ve bu veriler genellikle güncel olmayabilir veya belirli uygulamalar için uygun olmayabilir. Ayrıca, yetenekleri metin üretimi ile sınırlıdır. Ayrıca, LLM’lerin bazı görevler için çalışmadığını, örneğin karmaşık hesaplamalar gibi görevleri gerçekleştiremediklerini gördük.
Bu bölüm, GPT-4'ün devrim niteliğinde bir özelliğine odaklanıyor: eklentiler (GPT-3.5 modelinin eklenti işlevine erişimi olmadığını unutmayın). Yapay zeka evriminde, eklentiler, etkileşimi yeniden tanımlayan yeni bir dönüştürücü araç olarak ortaya çıkmıştır. Eklentilerin amacı, LLM’ye daha geniş yetenekler kazandırmaktır; bu da modele gerçek zamanlı bilgiye erişim sağlar, karmaşık matematiksel hesaplamalar yapmasına izin verir ve üçüncü taraf hizmetlerini kullanmasına olanak tanır.
En başta, modelin 3,695 × 123,548 gibi karmaşık hesaplamaları gerçekleştiremediğini gördük. Aşağıdaki şekilde, Hesap Makinesi eklentisini etkinleştiriyoruz ve modelin gerektiğinde hesaplama yapması gerektiğinde otomatik olarak hesap makinesini çağırdığını görebiliyoruz, böylece doğru çözümü bulmasına izin veriliyor.
