Veri Biliminde Python ile SEO Otomasyonu

Python Kullanarak Veri Bilimi ile SEO Zorluklarının Çözümü
Derin SEO (Veri) Bilimi
Veri bilimini SEO’ya uygulamaya teşvik eden birçok trend bulunmaktadır; ancak önce şuna değinelim: Neden veri bilimcileri SEO endüstrisinin kapısına koşmuyor? Neden bunun yerine ücretli arama, programlı reklamcılık ve kitle planlaması gibi alanlara yöneliyorlar?
- Gürültülü geri besleme döngüsü
- Kanalın azalan değeri
- Reklamların organik listelemelere daha çok benzemesi
- Örnek veri eksikliği
- Ölçülemeyen şeyler
- Yüksek maliyetler
Veri biliminin SEO ile buluştuğu noktayı keşfettikçe, bu birleşmenin zorluklardan yoksun olmadığı açığa çıkar. Ancak, bu zorluklar, arama motoru dinamiklerinin labirentinden çıkarılabilecek aydınlatıcı görüşlerin potansiyelini gölgelemektedir. Bu karmaşık ilişki, dijital peyzajları yeniden şekillendirmek ve işletmeleri çevrimiçi ekosistemlerdeki her zaman ulaşılamayan üstünlüğe doğru yönlendirmek için güce sahiptir
Numune Veri Eksikliği
Veri noktalarının eksikliği, veri odaklı SEO analizini daha zorlu hale getiren bir faktördür. Ne kadar sık bir SEO teknik denetim yapmıştır ve bunu SEO gerçeğinin bir yansıması olarak almıştır? Bu web sitesinin belirli bir denetim sırasında kötü bir anı yaşamadığını nereden bilebiliriz?
Neyse ki, sektör lideri sıralama ölçüm araçları günlük bazda sıralamaları kaydediyor. Peki neden SEO ekipleri daha düzenli bir temelde denetim yapmıyor?
Birçok SEO ekibi, birden fazla ölçüm yapmak için altyapıya sahip değil çünkü çoğunluğun buna sahip olma imkanı yok, çünkü
- Veri bilimi için birden fazla ölçümün değerini anlamıyorlar
- Kaynakları veya altyapıyı bulundurmuyorlar
- Web sitesi değişikliklerini bilmek için başka bir denetim yapmadan önce beklemeyi tercih ediyorlar (ContentKing gibi araçlar bu süreci otomatik hale getirse de)
SEO gerçeğinin gerçek bir temsilini sağlayan bir veri kümesine sahip olmak için birden fazla denetim ölçümüne ihtiyaç vardır. Bu, günlük ortalama ve standart sapmalar gibi istatistiklere olanak tanır ve bunlar
- Sunucu durum kodları
- Yinelemeli içerik
- Eksik başlıklar
Bu tür verilerle, veri bilimcileri anlamlı SEO bilimsel çalışmaları yapabilir ve bunları sıralamalar ve kullanıcı deneyimi sonuçlarıyla takip edebilirler.
Ölçülemez Şeyler
Veriyi toplama konusunda en iyi niyetle bile, ölçmeye değer olan her şey ölçülemeyebilir. Bu muhtemelen sadece SEO değil, tüm pazarlama kanalları için geçerli bir durumdur; ancak bu, veri bilimcilerinin SEO’ya geçmemesinin en büyük nedeni değildir. Eğer bir şey söylemek gerekirse, SEO’da birçok şey ölçülebilir ve SEO veri bakımından zengindir.
Ölçmek istediğimiz bazı şeyler şunlar olabilir:
- Arama sorgusu: Google, bir süredir organik trafiğin arama sorgusu detayını gizliyor ve Google Analytics’teki anahtar kelime detayı “Sağlanmadı” olarak gösteriliyor. Elbette, bu bir URL’ye çok sayıda anahtar kelime ilişkisi olduğundan, ayrıntıların kırılımını elde etmek, dönüşüm modelleme sonuçları için (örneğin potansiyel müşteriler, siparişler ve gelirler) önemli olacaktır.
- Arama hacmi: Google Ads, arama sorgusu başına arama hacmini tam olarak açıklamaz. Uzun kuyruklu ifadeler için Ads tarafından sağlanan arama hacmi verisi, daha geniş eşleşmelere yeniden tahsis edilir çünkü Google için bu terimler üzerindeki kullanıcıların teklif vermesini teşvik etmek karlıdır, çünkü açık artırmada daha fazla teklif veren bulunur. Google Search Console (GSC) iyi bir alternatiftir, ancak ilk taraf verisidir ve hipotez anahtar kelimeniz için sitenizin varlığına son derece bağımlıdır.
- Segment: Bu, sadece anahtar kelimenin değil, kimin arama yaptığını bize söyler ve elbette bir milyonerin “erkek kot pantolon” aramasıyla daha mütevazı bir kullanıcının beklediği sonuçlar büyük ölçüde farklı olacaktır. Sonuçta, Google kişiselleştirilmiş sonuçlar sunuyor. Segmenti bilmemek, herhangi bir SERP modeline veya başka bir modele gürültü ekler.
Yüksek Miktarlar
Botify gibi geniş ölçekli bir işletme tarama teknolojisiyi günlük olarak çalıştırmayı düşünün. Birçok marka maliyet nedeniyle bu taramayı ayda bir kez çalıştırır; ve sadece kendi siteniz için değil. Tam bir veri kümesine ulaşmak için rakiplerinizde de çalıştırmanız gerekecektir ve bu sadece bir tür SEO verisi.
Maliyet, reklam ajansı veri bilimcisi için o kadar önemli olmayabilir, ancak ajans veriye erişim sağlayıp sağlamayacağına etki edecektir çünkü ajans, bütçenin değmeyeceğine karar verebilir.
Neden SEO İçin Veri Bilimine Yönelmelisiniz?
SEO kampanya ve operasyonlarınızı veri odaklı hale getirmek için veri bilimine yönelmeniz için birçok neden bulunmaktadır.
- SEO Veri Açısından Zengin Bir Alandır : Her şeyi ölçmek için elimizde Google’ın Arama Motoru Sonuç Sayfalarında (SERP’ler) listelenen web sitelerine kullanıcı tepki verisi de dahil olmak üzere her şeyin verisi bulunmamaktadır; bu, nihai sonuç verileri olurdu. Sahip olduğumuz şey, birincil kaynak (sizin/sizin şirketinizin verileri gibi Google/Adobe Analytics) ve üçüncül kaynak (sıralama kontrol araçları, bulut denetimi yazılımları gibi) dışa aktarım verileridir.
Ayrıca, bu verileri anlamak için ücretsiz olan açık kaynak veri bilimi araçlarımız bulunmaktadır. Ayrıca, SEO verisinin sürekli artan selini anlamak için bu araçları nasıl kullanacağınızı öğretmeye istekli birçok ücretsiz ve son derece güvenilir çevrimiçi kaynak bulunmaktadır. - SEO Otomatize Edilebilir: En azından belirli yönlerde. Kariyerinizin tamamen robotlar tarafından ele geçirileceğini söylemiyoruz. Yine de, SEO uzmanı olarak yaptığınız işin bazı yönlerinin bilgisayarlar tarafından yerine getirilebileceği bir durum olduğuna inanıyoruz. Sonuçta, bilgisayarlar tekrarlayan görevleri yapma konusunda son derece iyidir, yorulmazlar veya sıkılmazlar, üç boyutun ötesini “görebilirler” ve sadece elektrikle çalışırlar.
Bilgisayarın kolayca yapabileceği tekrarlayan işleri yapmak, değer katmayan, duygusal olarak çekici olmayan ve zihinsel sağlığınız için iyi olmayan bir şeydir. Önemli olan, insan olarak en iyi olduğumuz zaman, bir müşterinin SEO çalışmaları hakkında düşünerek ve bilgiyi sentezleyerek çalışmamızdır; işte en iyi işimizi yaptığımız zaman budur. - Veri Bilimini Kullanmak Karlıdır: Bu verileri anlamak için ücretsiz olan açık kaynak veri bilimi araçlarına da sahibiz (R, Python). Ayrıca, SEO verisinin sürekli artan selini anlamak için bu araçları nasıl kullanacağınızı öğretmeye istekli birçok ücretsiz ve oldukça güvenilir çevrimiçi kaynak da bulunmaktadır.
Ayrıca, çok fazla veri varsa, Amazon Web Services (AWS) ve Google Cloud Platform (GCP) gibi bulut bilişim hizmetleri de saatlik kiralama ile kullanılabilir durumdadır.
Anahtar Kelime Araştırması
Her arama motoruna giren kullanıcının arkasında bir kelime veya kelime dizisi bulunur. Örneğin, bir kullanıcı “otel” veya belki de “İstanbul’da otel” arayışında olabilir. Arama motoru optimizasyonunda (SEO), anahtar kelimeler kaçınılmaz olarak hedeflenen unsurlardır. Bu, belirli sorguların talebini anlamada yardımcı olan ve ürünler, hizmetler, organizasyonlar ve sonuç olarak cevaplar için kullanıcıların farklı arama yollarını daha etkili bir şekilde anlamada yardımcı olan faydalı bir yoldur.
Anahtar kelimelerle başlayan SEO’nun yanı sıra, bir SEO kampanyası, anahtar kelimenin katkısının değerlendirilmesiyle sonlanma eğilimindedir. Bu bilgi Google tarafından bizden gizlense de, birçok SEO aracı, bir web sitesine ulaşmak için kullanıcıların kullandığı anahtarı çıkarmaya yönelik çabalar göstermiştir.
Şimdi, web siteniz için değerli anahtar kelimeleri bulmak için veri odaklı yöntemleri sunacağız (kullanıcı talebinin daha zengin bir anlayışına sahip olmanıza olanak tanımak için).
Ayrıca, anahtar kelime sıralama izleme maliyeti gerektirir (genellikle izlenen anahtar kelime başına ücretlendirilir veya toplamda izlenecek anahtar kelime sayısına sınırlama getirilir), bu nedenle hangi anahtar kelimelerin izleme maliyetine değer olduğunu bilmek mantıklıdır.
Anahtar Kelimeler İçin Veri Kaynakları
Anahtar kelime araştırması konusunda kullanılabilecek birkaç veri kaynağı bulunmaktadır. Bunları aşağıdaki gibi sıralayabiliriz:
- Google Search Console
- Rakip Analitikleri
- SERP Sonuçları (Arama Motoru Sonuç Sayfaları)
- Google Trends
- Google Ads
- Google Önerileri
Kalın harflerle vurgulananları ele alacağız, çünkü bu veri kaynakları hem daha bilgilendirici hem de veri bilimi yöntemleri açısından ölçeklenebilir. Google Ads verileri yalnızca gerçek kullanım verilerine dayanıyorsa bir o kadar kullanışlı olurdu.
Ayrıca, hem 1. sayfa sıralaması (1 ila 10 arasındaki pozisyonlar arasında) elde ederseniz ne kadar izlenim alabileceğinizi hem de bu etkinin altı aylık bir süre boyunca nasıl olacağını tahmin etmenizi göstereceğiz.
Müşterilerin nasıl arama yaptığına dair ayrıntılı bir anlayışla, dizinlediğiniz yerin bu talebe göre nasıl bir konumda olduğunu karşılaştırarak (bu fırsata ne kadar yaklaşabileceğinizi anlamak için) daha güçlü bir konumda olursunuz ve aynı zamanda web sitenizi ve SEO faaliyetinizi bu talebi hedeflemek üzere müşteri odaklı hale getirirsiniz. Haydi başlayalım.
Google Search Console (GSC)
Google Search Console (GSC), zengin pazar istihbaratına sahip olan (ücretsiz) bir birinci taraf veri kaynağıdır. Google’ın API’sini tarih ve anahtar kelime düzeyinde sorgulama girişimlerinde veriyi çözümlemeyi zorlaştırmak için elinden geleni yapmasına ve hatta veriyi belirsizleştirmesine şaşmamalıdır.
Anahtar kelime araştırması söz konusu olduğunda GSC verileri uzmanların ilk başvurduğu öncelikli kaynaktır çünkü sayılar tutarlıdır ve üçüncü taraf verilerinin aksine sıralamaya haritalanan genel tıklama oranına dayanmayan veriler alırsınız.
Genel strateji, sıralama pozisyonlarına göre ortalamanın üzerinde belirgin bir şekilde görünen izlenimlere sahip arama sorgularını aramaktır. Neden izlenimler? Çünkü izlenimler daha bol miktarda bulunur ve fırsatı temsil eder, oysa tıklamalar genellikle sonradan gelir, yani fırsatın sonucudur. Ne anlam taşır? Örneğin, izlenim seviyeleri ortalamanın üzerinde iki standart sapmanın (sigma) üzerinde olan herhangi bir arama sorgusu olabilir.
Veriyi İçe Aktarma, Temizleme ve Düzenleme
Öncelikle gerkeli kütüphaneleri kodumuza dahil edelim.
import pandas as pd
import numpy as np
import glob
import osVeri, bir dizi filtre temelinde en üst 1000 satırın Google Search Console (GSC) dışa aktarmalarından oluşuyor.
Şu an için, yerel bir klasörde depolanan birden çok GSC dışa aktarma dosyasını okuyoruz. Dosyaları okumak için yolunuzu ayarlayın:
data_dir = os.path.join('data', 'csvs')
gsc_csvs = glob.glob(data_dir + "/*.csv")Okuduğumuz veriyi kaydetmek için boş bir liste oluşturalım:
gsc_li = [] // or list()Şimdi ise verilerimizi bir döngüye alarak yeni listemize ekleyelim:
for cf in gsc_csvs:
df = pd.read_csv(cf, index_col=None, header=0)
df['modifier'] = os.path.basename(cf)
df.modifier = df.modifier.str.replace('_queries.csv', '')
gsc_li.append(df)Şimdi ise bu verileri tek bir çerçevede birleştirelim
gsc_raw_df = pd.DataFrame()
gsc_raw_df = pd.concat(gsc_li, axis=0, ignore_index=True)Şimdi ise sütunlarımızı daha kullanıcı dostu hale getirelim:
gsc_raw_df.columns = gsc_raw_df.columns.str.strip().str.lower().str.
replace(' ', '_').str.replace('(', '').str.replace(')', '')
gsc_raw_df.head()Bu işlemden sonra sütunlar alttaki şekilde gözükecek:
Şimdi birde yüzdelik verilerimizi daha okunaklı hale getirebilmek için bir işlem yapalım:
gsc_clean_ctr_df['ctr'] = gsc_clean_ctr_df['ctr'].str.replace('%', '')
gsc_clean_ctr_df['ctr'] = pd.to_numeric(gsc_clean_ctr_df['ctr'])Ve bizim işimize yarar olan anahtar kelimeleri tespit etmek için 10 tıklanmanın altındaki anahtar kelimeleri silelim.
gsc_clean_ctr_df['impressions'] = gsc_clean_ctr_df.impressions.str.
replace('<', '')
pd.to_numeric(gsc_import_df.impressions)Son olarak ise top_queries’e göre sıralayalım.
gsc_dedupe_df = gsc_clean_ctr_df.drop_duplicates(subset='top_queries',
keep="first")Şimdi ise sıra farklı bir bölümleme türünde.
Sorgu Türüne Göre Bölümle
Bir sonraki adım, sorguları türe göre bölümlemektir. Bunun nedeni, genel web sitesi yerine bir segment içindeki izlenim hacimlerini karşılaştırmak istememizdir. Bu, sayıları segment içindeki fırsatları vurgulama açısından daha anlamlı hale getirir. Aksi takdirde, izlenimleri web sitesi ortalamasına göre karşılaştırsak, değerli arama sorgusu fırsatlarını kaçırabiliriz. Python’da kullandığımız yaklaşım, sorgu sütununda bulunan değiştirici dizeler temelinde kategorilendirmektir:
retail_vex = ['cdkeys', 'argos', 'smyth', 'amazon', 'cyberpunk', 'GAME']
platform_vex = ['ps5', 'xbox', 'playstation', 'switch', 'ps4', 'nintendo']
title_vex = ['blackops', 'pokemon', 'minecraft', 'mario',
'outriders','fifa', 'animalcrossing', 'resident', 'spiderman',
'newhorizons', 'callofduty']
network_vex = ['ee', 'o2', 'vodafone','carphone']
gsc_segment_strdetect = gsc_dedupe_df[['query', 'clicks', 'impressions',
'ctr', 'position']]Koşullarımızın bir listesini oluşturalım:
query_conds = [
gsc_segment_strdetect['query'].str.contains('|'.join(retail_vex)),
gsc_segment_strdetect['query'].str.contains('|'.join(platform_vex)),
gsc_segment_strdetect['query'].str.contains('|'.join(title_vex)),
gsc_segment_strdetect['query'].str.contains('|'.join(network_vex))
]Her bir koşul için atamak istediğimiz değerlerin bir listesini oluşturalım:
segment_values = ['Retailer', 'Console', 'Title', 'Network'] #, 'Title',
'Accessories', 'Network', 'Top1000', 'Broadband']Yeni bir sütun oluşturun ve np.select’i kullanarak argüman olarak listelerimizi kullanarak değerleri atayalım:
gsc_segment_strdetect['segment'] = np.select(query_conds, segment_values)
gsc_segment_strdetectÇıktımız aşağıdaki gibi olacaktır:
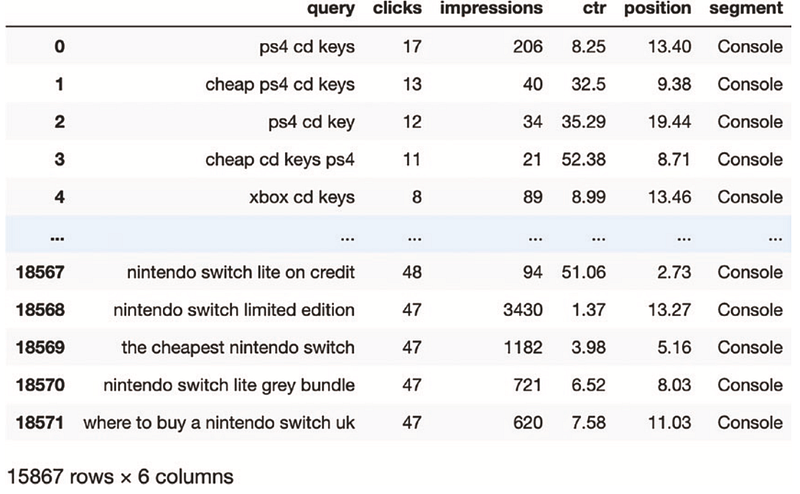
Şimdi ise isterseniz posizyon verilerimizi daha kullanışlı olması açısından tam sayılara yuvarlayalım.
gsc_segment_strdetect['rank_bracket'] = gsc_segment_strdetect.position.
round(0)
gsc_segment_strdetectKodumuzun son çıktısı aşağıdaki gibi olacaktır:

Şimdi ise bir adım ileriye giderek Segment Ortalamasını ve Değişkenliğini hesaplayalım
Şimdi veriyi bölümlere ayırdık, ortalama izlenimleri ve sıralama pozisyonu için alt ve üst yüzde dilimlerini hesaplıyoruz. Amaç, izlenimlerin, sıralama pozisyonundan iki standart sapma veya daha fazla yukarıda olduğu sorguları belirlemektir.
Bu, sorgunun muhtemelen SEO için büyük bir fırsat olduğu ve takip etmeye değer olduğu anlamına gelir.
Sadece yüksek izlenimli anahtar kelimeleri seçmek yerine bunu bu şekilde yapıyoruz, çünkü birçok anahtar kelime sorgusu zaten ilk 20'de olmaları nedeniyle yüksek izlenimlere sahiptir. Bu, takip edilmesi gereken sorgu sayısını oldukça büyük ve maliyetli hale getirebilir.
queries_rank_imps = gsc_segment_strdetect[['rank_bracket', 'impressions']]
group_by_rank_bracket = queries_rank_imps.groupby(['rank_bracket'], as_
index=False)
def imp_aggregator(col):
d = {}
d['avg_imps'] = col['impressions'].mean()
d['imps_median'] = col['impressions'].quantile(0.5)
d['imps_lq'] = col['impressions'].quantile(0.25)
d['imps_uq'] = col['impressions'].quantile(0.95)
d['n_count'] = col['impressions'].count()
return pd.Series(d, index=['avg_imps', 'imps_median', 'imps_lq', 'imps_uq', 'n_count'])
overall_rankimps_agg = group_by_rank_bracket.apply(imp_aggregator)
overall_rankimps_aggVe son aşamada kodumuz çalıştığında bu şekilde bir tablo karşımıza çıkacaktır.
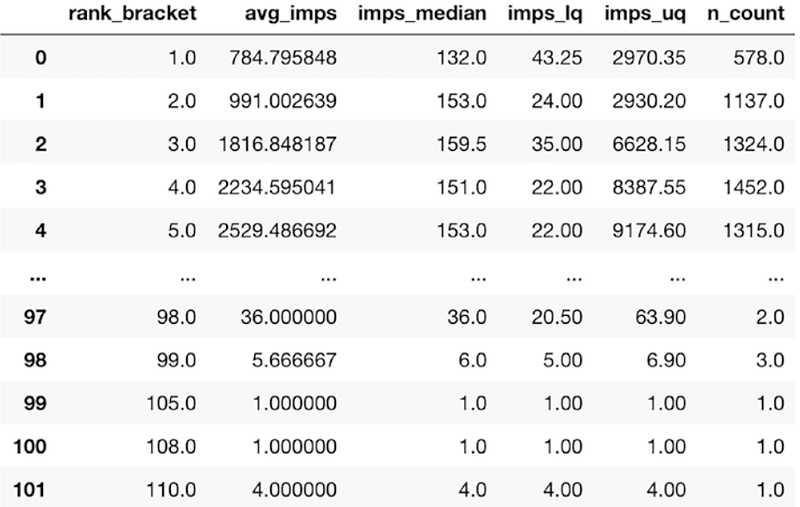
Bu durumda, 25. ve 95. yüzde dilimleriyle ilerledik. Alt yüzde dilimi sayısı pek önemli değil, çünkü ortalama değerleri 95. yüzde dilimin ötesinde olan sorguları bulmaktan daha fazla ilgileniyoruz. Bunu başarabilirsek, lezzetli bir anahtar kelime bulmuş oluruz. Hızlı bir not olarak, veri biliminde yüzde dilimi “çeyreklik” olarak bilinir.
Her bir bölüm için ayrı bir tablo oluşturabilir miyiz? Örneğin, bölüme göre sıralama pozisyonuna göre izlenim istatistiklerini gösterin. Evet, elbette yapabilirsiniz ve teorik olarak, sorguların bölüm ortalamasına göre nasıl performans gösterdiğine dair daha bağlamsal bir analiz sağlardı. Bunun yapılıp yapılmayacağına karar verme faktörü, her sıralama kategorisi için kaç veri noktanızın (yani sıralı sorgular) olduğuna ve bunu yapmaya değip değmeyeceğine (yani istatistiksel olarak güvenilir) bağlıdır. Bu tür bir analiz için her birinde en az 30 veri noktasına ihtiyaç duyarsınız.
Ortalama İzlenim Seviyelerini Karşılaştıralım
Şimdi önceki veri setinden gelen tabloyu birleştirelim (vlookup veya index match gibi düşünün) ve ardından bölümlendirilmiş verilere birleştirelim. Sonuç olarak, sorgu verilerini beklenen ortalama ve üst çeyreklikle karşılaştıran bir veri çerçevemiz olacak.
accessory_queries tablosunu accessories_rankimps_agg ile rank_bracket’e göre birleştirin (vlookup veya index match gibi düşünün).
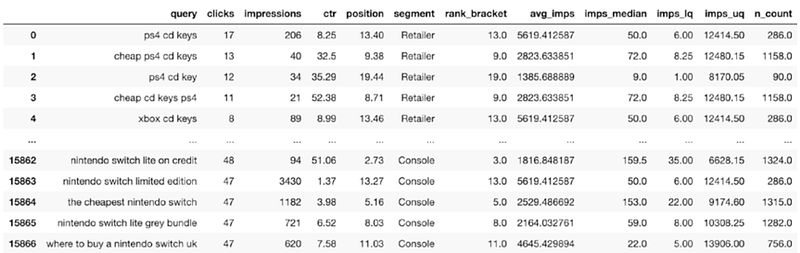
query_quantile_stats = gsc_segment_strdetect.merge(overall_rankimps_agg, on
=['rank_bracket'], how='left')
query_quantile_statsTablomuzun son hali bu şekilde olacaktır.
Veriyi Keşfedelim
Şimdi merak ediyor olabilirsiniz, kaç anahtar kelime ağırlığının üstünde ve altında (yani sıralama pozisyonuna göre çeyreklik sınırlarının üstünde ve altında) ve bu anahtar kelimeler neler?
Yüksek izlenim hacmine sahip anahtar kelimelerin sayısını alın:
query_stats_uq = query_quantile_stats.loc[query_quantile_stats.impressions
> query_quantile_stats.imps_uq]
query_stats_uq['query'].count()Ekrana yazılacak olan sonuç 8390 olacaktır.
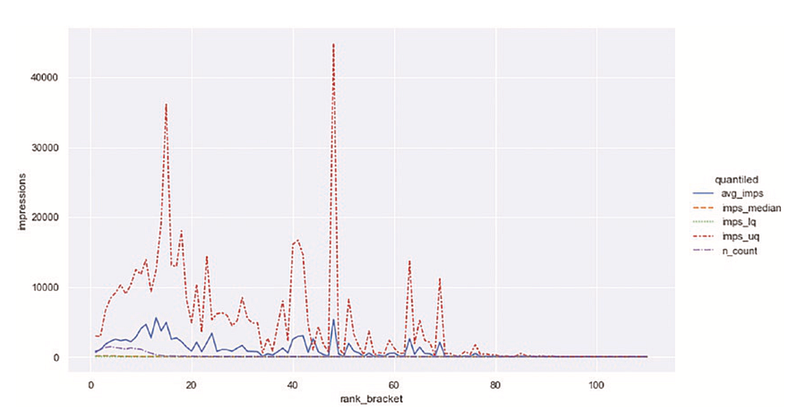
İzlenim dağılımının sıralama pozisyonları aralığında görsel olarak nasıl göründüğüne bakalım:
import seaborn as sns
import matplotlib.pyplot as plt
from pylab import savefig
sns.set(rc={'figure.figsize':(15, 6)})
imprank_plt = sns.relplot(x = "rank_bracket", y = "impressions",
hue = "quantiled", style = "quantiled",
kind = "line", data = overall_rankimps_agg_long)
imprank_plt.savefig("images/imprank_plt.png")İlginç olan, üst çeyreklik izlenim anahtar kelimelerinin hepsinin en üst 10'da olmadığıdır. Bu, sitenin ya yüksek hacimli anahtar kelimeleri hedeflediğini ancak yüksek bir sıralama pozisyonu elde etme konusunda başarılı olamadığını ya da bu yüksek hacimli ifadeleri hedeflemediğini gösterir.
Bu bölümü detaylı olarak inceleyelim.
İzlenimleri sıralama aralığına göre bölümle çizelim:
imprank_seg = sns.relplot(x="rank_bracket", y="impressions",
hue="quantiled", col="segment",
kind="line", data = overall_rankimps_agg_long, facet_
kws=dict(sharex=False))
imprank_seg.savefig("images/imprank_seg.png")Yüksek izlenimli anahtar kelimelerin çoğu Aksesuarlar, Konsol ve tabii ki En İyi 1000 kategorilerinde bulunuyor:

Veriyi CSV Olarak Dışa Aktaralım
query_stats_uq_p2b.to_csv('exports/verbilimi_seo.csv')