LangChain
Bağlam Mühendisliğine Giriş: LangChain Öğrenme Günlüğüm
2025’in sonbaharında yapay zekâ dünyasının nabzını tutan herkesi heyecanlandıran bir kavram ortaya çıktı: bağlam mühendisliği. Google’ın ADK mimarisi üzerine yazılan detaylı bir makale, klasik prompt mühendisliği yaklaşımının sınırlarını ve üretime hazır ajanlar geliştirirken karşılaşılan karmaşayı gözler önüne seriyordumedium.com. Bugün size, Mayo Oshin ve Nuno Campos’un Learning LangChain: Building AI and LLM Applications with LangChain and LangGraph kitabını okurken bu kavramla nasıl tanıştığımı ve öğrendiklerimi bir günlük havasında anlatmak istiyorum.
Yeni Bir Dönemin Kapısı
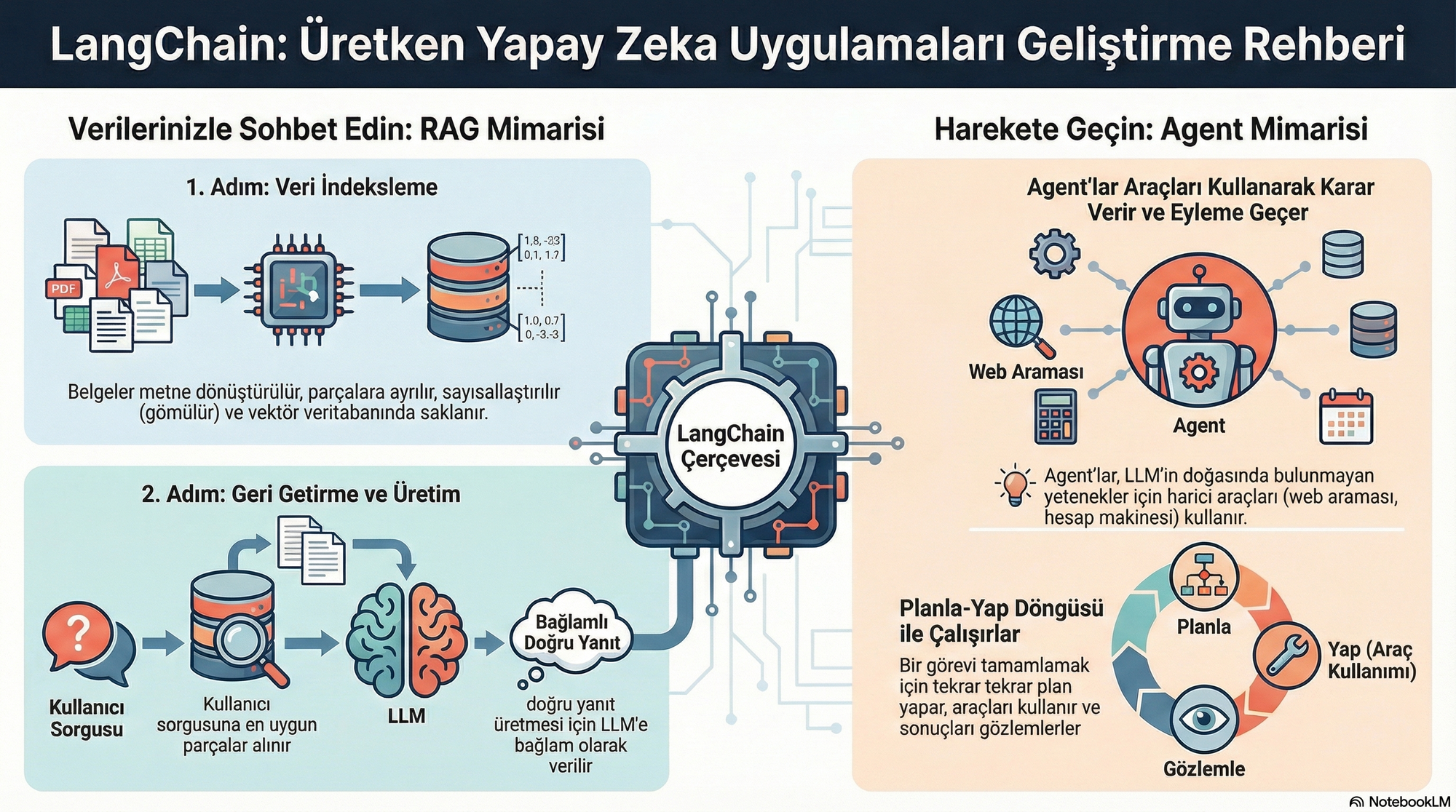
LangChain ve LangGraph günümüz LLM tabanlı uygulamalarının temel taşlarından biri haline geldi. İş dünyasında kişisel verilerle konuşabilen üretim düzeyinde sohbet robotları geliştirmek isteyenler için adeta bir rehber niteliğindebarnesandnoble.com. Kitap, Python veya JavaScript bilen ancak yapay zekâ uygulamalarında yeni olan geliştiricilerin bile rahatça takip edebileceği şekilde yazılmış. Retriever-Augmented Generation (RAG) yapısı, dil modellerinin dış veri kaynaklarıyla beslenerek daha güncel ve doğru yanıtlar vermesini sağlıyorbarnesandnoble.com.
Kitapta bölümler ilerledikçe RAG’in adımları, veri indeksleme ve veri tabanlı diyalog süreçleri ayrıntılı bir şekilde anlatılıyor. Özellikle PGVector gibi vektör veri tabanlarının nasıl entegre edileceği ve dizinleme sırasında kod bölme yöntemleri (örneğin RecursiveCharacterTextSplitter) üzerinde durulmuşsonim1.com. Bu bölümleri okurken, Google’ın ADK mimarisindeki bağlam derleyicisi benzetmesi aklıma geldi: ham geçmiş konuşma verileri ve değişkenler, modele gönderilmeden önce bir nevi derleniyormedium.com. LangChain’de de benzer şekilde, uzun dokümanlar anlamlı parçalara bölünüyor, vektör veritabanına kaydediliyor ve kullanıcı sorusu geldiğinde en ilgili bölümler hızlıca çekiliyor. Bu süreç bana derleyicilerin kodu makine diline çevirmesini hatırlattı.
İlk Deneyimlerim: Basitten Karmaşığa
Kitabın ilk bölümlerinde yazarlar, LangChain’in temel bileşenlerini kavramak için gerekli olan yapay zekâ bilgisine odaklanıyor. Ardından temel dil modeli kullanımını anlatarak, LangChain Expression Language (LCEL) ile özelleştirilmiş zincirler oluşturmanın inceliklerini öğretiyor. Bu kısımda öğrendiğim en önemli nokta, zincirlerin mantıksal akışını tanımlarken modüler düşünmenin gerekliliğiydi: her bir modül belirli bir işlemi üstleniyor ve karmaşık görevler bu modüllerin birleşmesiyle çözülebiliyor.
RAG’in ilk adımı olan veri dizinleme bölümünde, daha önce yalnızca karakter sayısına göre bölme işlemleri kullanırken şimdi programlama dillerine özel bölme stratejilerinden bahsedildiğini görmek beni şaşırttısonim1.com. Örneğin, Python kodlarını fonksiyon bloklarına göre bölmek veya Markdown belgelerinde başlık ve alt başlıkları dikkate almak, sorgu sırasında daha anlamlı sonuçlar elde etmemi sağladı. İkinci adım olan soru-cevap bölümünde ise çoklu sorgu üretimi (multi-query retrieval) ve Reciprocal Rank Fusion (RRF) gibi kavramlarla tanıştımsonim1.com. Farklı ifadelerle oluşturulan sorguların birleştirilmesi, tek bir sorguya göre daha zengin ve çeşitli sonuçlar üretiyor.
Bu noktada, Google’ın makalesinde değinilen “bağlam penceresi ikilemi”ne geri dönmek istiyorum: tarihçe ne kadar uzun olursa, maliyet ve gecikme o kadar artıyormedium.com. LangChain’de farklı sorgu stratejilerini uygulamak, gerçekten gerekli bilgiyi kısa ve öz bir bağlama indirgemek anlamına geliyor. Çeşitli sorgularla gelen sonuçlar RRF ile bir araya getirildiğinde gereksiz gürültü azalıyor ve bağlam penceresi daha verimli kullanılıyor.
LangGraph ile Zihin Haritaları
Kitapta beni en çok heyecanlandıran bölümlerden biri LangGraph oldu. Zincir yapılarının sınırlarını aşmak için geliştirilen bu framework, karmaşık iş akışlarının düğüm ve kenarlardan oluşan grafiklerle modellenmesine olanak tanıyorsonim1.com. Çoklu ajan işbirliği, çok adımlı akıl yürütme veya dinamik karar ağaçları gibi senaryolarda zincir yapıları yeterli olmuyor. LangGraph’te her düğüm bir işlem, kenarlar ise veri akışı; yani adeta bir düşünce haritası çiziyorsunuz.
Google’ın ADK mimarisindeki Akışlar (Flows) ve İşleyiciler (Processors) kavramları da benzer şekilde bağlamı derleme ve enjekte etme süreçlerini modüler hale getiriyormedium.com. Kitaptaki grafik odaklı yaklaşım ile ADK’nin modüler bağlam derlemesi arasındaki paralelliği görmek, iki farklı ekosistemin aynı problemleri nasıl çözdüğünü anlamamı sağladı. Örneğin, bir kullanıcı sorusunu ele alırken önce bellekten ilgili geçmiş çağrışımları çeken bir düğüm, ardından dış API’lere başvuran bir düğüm ve son olarak cevabı oluşturan bir dil modeli düğümü tasarlayabilirsiniz. Bu düğümler arasındaki akışı düzenlemek, kodun okunabilirliğini artırıyor ve test etmeyi kolaylaştırıyor.
RAG’in Ötesinde: Değerlendirme ve İzleme
Kitabın ilerleyen bölümlerinde, geliştirilen uygulamaların test edilmesi, izlenmesi ve iyileştirilmesi konularına özel bir bölüm ayrılmışsonim1.com. Pek çok geliştirici için bu konular genellikle ikinci planda kalır; ancak üretim ortamında çalışan sohbet robotları söz konusu olduğunda, performansın ölçülmesi ve hataların tespiti hayati önem taşıyor. Bu bölümde; metin değerlendiriciler, insan geribildirimi ve otomatik testler aracılığıyla modellerin nasıl izleneceğini öğrendim. Ayrıca, hatalı veya yetersiz cevapların nedenlerini anlamak için prompt tamamlama günlüklerinin tutulmasının önemine dikkat çekiliyor.
Bu noktada Google’ın makalesindeki bağlam filtreleme ve seçici enjeksiyon vurgusu ile kitapta anlatılan değerlendirme stratejileri arasında güçlü bir bağ kurdum. Hangi bilginin modele verilmesi gerektiğine karar vermek kadar, verilen bilginin sonuç üzerindeki etkisini ölçmek de kritik. Yanlış bir kaydı bağlamdan çıkarmak, doğru bir kaydı en iyi yerde enjekte etmek kadar önemlidir.
Kişisel Düşünceler ve Geleceğe Bakış
Kitabı bitirdiğimde, LangChain ve LangGraph’in yalnızca birer kütüphane değil, bağlam mühendisliği yaklaşımının somut birer örneği olduğunu fark ettim. Google’ın ADK mimarisi bağlamı derlenebilir bir varlık olarak tanımlarkenmedium.com, LangChain de bağlamı modüller hâlinde işleyip dil modellerine en uygun şekilde sunuyor. Bu süreçleri öğrenirken, kendi projelerimde gereksiz uzun konuşma geçmişlerini nasıl kısaltacağımı, dış kaynaklardan elde ettiğim bilgileri nasıl en verimli şekilde birleştireceğimi düşünmeye başladım.
Bir mühendis olarak, günlüğümde deneyimlerimi samimi bir dille paylaşmak istedim. Çünkü bu teknolojilerin arkasında sadece kod değil, bir düşünce yapısı ve problem çözme felsefesi var. LangChain’in modülerliği ve grafik yapılarının esnekliği bana yalnızca teknik beceriler kazandırmadı; aynı zamanda bağlam bilinci (context awareness) ve yapılandırılmış düşünme konularında da yeni ufuklar açtı.
Sonuç olarak, Learning LangChain kitabı, yapay zekâ uygulamaları geliştirmek isteyen herkes için değerli bir rehber. Google’ın ADK makalesinde bahsedilen prensiplerle birlikte ele alındığında, bağlam mühendisliğinin neden geleceğin anahtar kavramlarından biri olduğunu daha iyi anlıyorsunuz. Eğer siz de veri ile zenginleştirilmiş, güvenilir ve ölçeklenebilir AI çözümleri geliştirmek istiyorsanız, bu kitabı okurken tuttuğum bu günlük notlar size ilham verebilir.
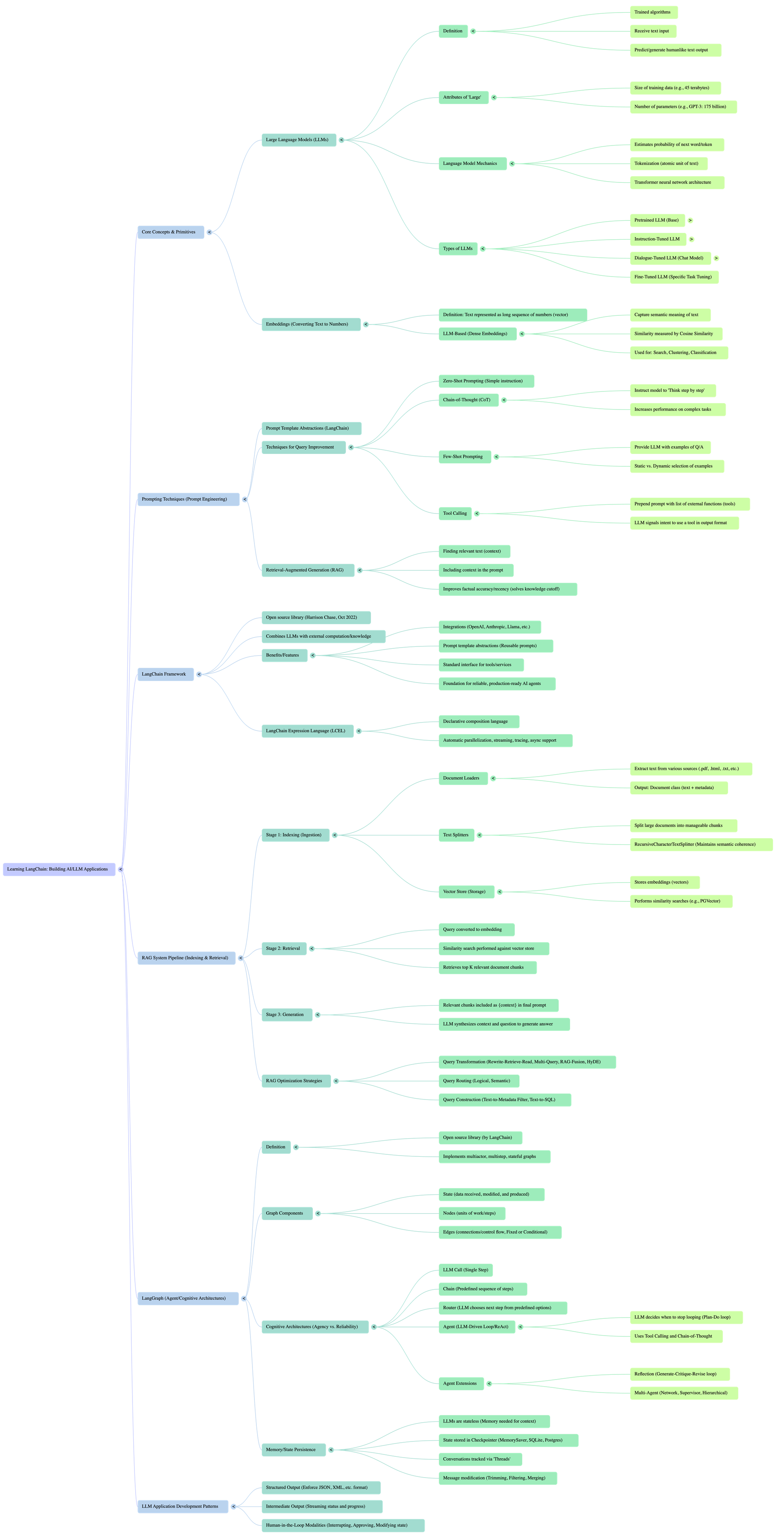
SORU - CEVAP
| Büyük Dil Modelleri (LLM'ler) bağlamında, bir 'token' neyi temsil eder? | Metnin atomik bir birimini temsil eder; bu bir karakter, kelime, alt kelime veya daha büyük bir dilsel birim olabilir. |
| Büyük Dil Modellerinin (LLM) öngörü gücünün arkasındaki ana motor _____ sinir ağı mimarisi olarak bilinir. | Transformer |
| Bir LLM'ye sağlanan talimatlara ve girdi metnine ne ad verilir? | Prompt (Yönlendirme) |
| Modelin çıktısının kalitesini önemli ölçüde etkileyebilen yönlendirme tasarlama pratiğine ne denir? | Prompt engineering (Yönlendirme mühendisliği) |
| Önceden eğitilmiş bir LLM'yi, göreve özel veri setleri üzerinde ek eğitimle iyileştirme sürecine ne ad verilir? | Fine-tuning (İnce ayar) |
| İnsan Geri Bildiriminden Güçlendirmeli Öğrenme (RLHF) hangi amaçla kullanılır? | Önceden eğitilmiş LLM'leri, kullanıcıların model çıktılarına verdiği geri bildirimlerle daha da iyileştirmek için kullanılır. |
| LangChain'de bir 'Chat Model' arayüzü, 'LLM' arayüzünden temel olarak nasıl farklılaşır? | Chat Model arayüzü, mesajları 'sistem', 'kullanıcı' ve 'asistan' gibi rollere ayırarak ileri geri konuşmaları yönetmek için tasarlanmıştır. |
| Dinamik girdilerle yönlendirmeler oluşturmayı kolaylaştıran LangChain arayüzüne ne ad verilir? | Prompt Template (Yönlendirme Şablonu) |
| LangChain'de, bir dil modelinin metinsel çıktısını liste, XML veya JSON gibi daha yapılandırılmış bir formata dönüştüren sınıflara ne denir? | Output Parsers (Çıktı Ayrıştırıcıları) |
| Sıfır vuruşlu (Zero-Shot) yönlendirme tekniği nedir? | LLM'ye herhangi bir örnek vermeden, sadece istenen görevi yerine getirmesi için talimat vermekten oluşan en basit yönlendirme tekniğidir. |
| Düşünce Zinciri (Chain-of-Thought) yönlendirmesi, LLM performansını nasıl artırır? | Modeli, bir cevaba nasıl ulaşacağını adım adım açıklaması için yönlendirerek, özellikle mantıksal akıl yürütme gerektiren görevlerde performansı artırır. |
| Artırılmış Geri Alımlı Üretim (RAG) tekniğinin temel amacı nedir? | Ansiklopedi gibi harici metinlerden ilgili parçaları bularak ve bu bağlamı yönlendirmeye dahil ederek LLM'nin doğruluğunu ve bilgisini artırmaktır. |
| Bir LLM'nin harici fonksiyonları kullanmasını sağlayan yönlendirme tekniğine ne ad verilir? | Tool Calling (Araç Çağırma) |
| Az vuruşlu (Few-Shot) yönlendirme nedir? | LLM'ye, yeni bir görevi nasıl yerine getireceğini öğrenmesi için birkaç soru ve doğru cevap örneği sağlama tekniğidir. |
| LangChain, LLM uygulamaları oluşturmayı neden kolaylaştırır? | LLM sağlayıcıları ile entegrasyonlar, yeniden kullanılabilir bileşenler (şablonlar, araçlar) ve bu bileşenleri birleştirmek için soyutlamalar sağlayarak kolaylaştırır. |
| LangChain Expression Language (LCEL) kullanarak bileşenleri birleştirmenin (bildirimsel kompozisyon) bir avantajı nedir? | Otomatik paralelleştirme, akış (streaming), izleme ve asenkron destek ile optimize edilmiş bir yürütme planı sunar. |
| Bir RAG sisteminde 'indeksleme (indexing)' adımının amacı nedir? | Belgeleri, uygulamanın her soru için en alakalı olanları kolayca bulabileceği bir şekilde ön işlemden geçirmektir. |
| Metni, anlamını koruyan sayısal bir temsile (genellikle uzun bir sayı dizisi) dönüştürme işlemine ne denir? | Embedding (Gömme) |
| İki vektör arasındaki anlamsal benzerlik derecesini ölçmek için kullanılan yaygın bir yöntem nedir? | Kosinüs Benzerliği (Cosine Similarity) |
| LangChain'de, çeşitli kaynaklardan (örneğin .txt, .pdf, web sayfası) veri yükleyip metin ve meta veriden oluşan bir 'Document' sınıfına dönüştüren bileşenlere ne denir? | Document Loaders (Belge Yükleyiciler) |
| Büyük belgeleri anlamsal olarak ilişkili metin parçalarını bir arada tutarak küçük, yönetilebilir parçalara ayırmak için kullanılan LangChain aracı nedir? | RecursiveCharacterTextSplitter |
| Vektörleri (embeddings) depolamak ve kosinüs benzerliği gibi karmaşık hesaplamaları verimli bir şekilde yapmak için tasarlanmış özel veritabanına ne ad verilir? | Vector Store (Vektör Deposu) |
| Kullanıcının sorgusuna dayalı olarak bir vektör deposundan ilgili gömmeleri ve belge parçalarını getirme sürecine ne ad verilir? | Retrieval (Geri Alım) |
| Yeniden Yaz-Geri Al-Oku (Rewrite-Retrieve-Read) stratejisi, temel RAG sistemlerindeki hangi sorunu çözmeyi amaçlar? | Kullanıcının sorgusunun kalitesindeki değişkenliği (örneğin, kötü ifade edilmiş veya belirsiz sorgular) ele alarak geri alım doğruluğunu artırmayı amaçlar. |
| Çoklu-Sorgu (Multi-Query) geri alım stratejisi nasıl çalışır? | Bir LLM'ye, kullanıcının ilk sorgusuna dayalı olarak birden fazla sorgu ürettirir, her sorgu için paralel olarak geri alım yapar ve sonuçları birleştirir. |
| RAG-Fusion stratejisi, çoklu-sorgu sonuçlarını birleştirmek için hangi algoritmayı kullanır? | Farklı arama sonuçlarının sıralamalarını birleştirerek tek bir birleşik sıralama üreten Karşılıklı Sıra Füzyonu (Reciprocal Rank Fusion - RRF) algoritmasını kullanır. |
| Varsayımsal Belge Gömme (HyDE) stratejisinin arkasındaki temel fikir nedir? | LLM tarafından oluşturulan varsayımsal bir belgenin, orijinal sorgudan daha çok ilgili belgelere benzer olacağı ve böylece daha iyi geri alım sonuçları vereceği fikridir. |
| Sorgu Yönlendirme (Query Routing) ne zaman faydalıdır? | Gerekli veriler ilişkisel veritabanları veya farklı vektör depoları gibi çeşitli veri kaynaklarında bulunduğunda, sorguyu uygun kaynağa yönlendirmek için faydalıdır. |
| Sorgu Oluşturma (Query Construction) süreci nedir? | Doğal bir dil sorgusunu, etkileşimde bulunulan veritabanının veya veri kaynağının sorgu diline (örneğin, SQL) dönüştürme sürecidir. |
| Bir sohbet robotu uygulamasında 'bellek (memory)' sisteminin rolü nedir? | Önceki konuşmaları ve bağlamı takip ederek LLM'nin durum bilgisi olmadan (stateless) çalışmasını telafi eder ve geçmiş etkileşimlere dayalı yanıtlar vermesini sağlar. |
| LangGraph, LangChain'in üzerine ne tür yetenekler ekler? | Çok aktörlü, çok adımlı, durum bilgili bilişsel mimariler (graflar) uygulamak için tasarlanmış bir kütüphanedir ve karmaşık ajan sistemleri oluşturmayı sağlar. |
| Bir LangGraph'ın üç temel bileşeni nedir? | Durum (State), Düğümler (Nodes) ve Kenarlar (Edges). |
| LangGraph'da bir 'düğüm (node)' neyi temsil eder? | Alınacak bir adımı veya bir iş birimini temsil eder ve genellikle mevcut durumu girdi olarak alan bir fonksiyondur. |
| LangGraph'da 'koşullu kenarlar (conditional edges)' ne için kullanılır? | Bir düğümden sonra hangi sonraki düğüme gidileceğine karar vermek için kullanılır, bu da grafikte dallanma ve döngülere olanak tanır. |
| LLM uygulamaları oluştururken karşılaşılan temel ödünleşim (trade-off) nedir? | Özerklik (agency) ile güvenilirlik (reliability) arasındaki ödünleşimdir. |
| Bir LLM uygulamasının otonom hareket etme kapasitesine _____ denir. | Agency (Özerklik) |
| Bilişsel mimariler spektrumunda, 'Zincir (Chain)' mimarisi ile 'Yönlendirici (Router)' mimarisi arasındaki temel fark nedir? | Zincir mimarisi önceden tanımlanmış bir adımlar dizisini yürütürken, yönlendirici mimarisi atılacak sonraki adımı seçmek için bir LLM kullanır. |
| Bir LLM'nin önceden tanımlanmış bir şemaya uygun, makine tarafından okunabilir formatta (örneğin JSON) çıktı üretmesini sağlamaya ne ad verilir? | Structured Output (Yapılandırılmış Çıktı) |
| Uzun süren LLM uygulamalarında kullanıcı deneyimini iyileştirmek için, uygulama çalışırken ilerleme veya ara çıktıları iletme tekniğine ne ad verilir? | Streaming/Intermediate Output (Akış/Ara Çıktı) |
| İnsan-Döngüde (Human-in-the-Loop) modelleri, yüksek özerkliğe sahip mimarilerde neden önemlidir? | Uygulama çalışırken bir insanın müdahale etmesine (örneğin, eylemleri onaylamasına veya durdurmasına) izin vererek güvenilirliği artırır. |
| Bir 'ajan (agent)' mimarisini diğerlerinden ayıran temel özellik nedir? | Ne zaman duracağına karar vermek de dahil olmak üzere bir döngüyü kontrol etmek için bir LLM'nin kullanılmasıdır; bu planla-yap (plan-do) döngüsü olarak bilinir. |
| ReAct olarak bilinen ajan mimarisi, hangi iki yönlendirme tekniğini birleştirir? | Araç Çağırma (Tool Calling) ve Düşünce Zinciri (Chain-of-Thought) tekniklerini birleştirir. |
| Bir ajan uygulamasında, her zaman belirli bir aracı (örneğin, bir arama aracı) ilk olarak çağırmayı zorunlu kılmanın potansiyel bir avantajı nedir? | Genel gecikmeyi azaltır ve LLM'nin aracı çağırmaması gereken durumlarda yanlışlıkla çağırmasını önler. |
| Bir ajana çok sayıda araç verildiğinde performansın düşmesi sorununa yönelik bir çözüm nedir? | Mevcut sorgu için en alakalı araçları önceden seçmek üzere bir RAG adımı kullanmak ve LLM'ye sadece bu alt kümeyi sunmaktır. |
| Yansıma (Reflection) veya öz-eleştiri (self-critique) tekniği, bir LLM uygulamasının performansını nasıl iyileştirebilir? | Uygulamaya geçmiş çıktılarını ve seçimlerini analiz etme ve sonraki revizyonları bilgilendirmek için bir eleştiri yazma fırsatı vererek iyileştirebilir. |
| Çoklu-ajan (Multi-agent) sistemleri hangi tür sorunları çözmek için kullanılır? | Tek bir ajanın başa çıkması için bağlamın çok karmaşık hale geldiği veya belirli alanlar için özel alt sistemler gerektiren sorunları çözmek için kullanılır. |
| Süpervizör (Supervisor) mimarisi, çoklu-ajan sisteminde nasıl çalışır? | Her ajan tek bir süpervizör ajanıyla iletişim kurar ve süpervizör, hangi ajanın (veya ajanların) bir sonraki adımda çağrılacağına karar verir. |
| LangGraph Platform'un birincil amacı nedir? | LangGraph ajanlarını ölçekte dağıtmak ve barındırmak için yönetilen bir hizmet sağlamaktır. |
| LangSmith, LLM uygulama geliştirme yaşam döngüsünde hangi işlevleri yerine getirir? | LLM uygulamalarını ayıklamak, işbirliği yapmak, test etmek ve izlemek için hepsi bir arada bir geliştirici platformu sağlar. |
| LLM uygulamalarının test edilmesinde 'regresyon testi' neden önemlidir? | Modeldeki veya uygulamadaki en son güncellemelerin, uygulamanın performansının temel bir sürüme göre gerilememesini (daha kötü performans göstermemesini) sağlamak için önemlidir. |
| Bir 'LLM-yargıç-olarak (LLM-as-a-judge)' değerlendiricisi ne yapar? | İnsan derecelendirme kurallarını bir LLM yönlendirmesine entegre ederek, uygulamanın çıktısının referans cevaba göre doğru olup olmadığını değerlendirir. |
| İkili değerlendirme (Pairwise evaluation), çıktıları değerlendirmeyi nasıl basitleştirir? | Bir uygulamanın farklı versiyonlarından iki çıktıyı aynı anda karşılaştırarak, hangisinin değerlendirme kriterlerini daha iyi karşıladığını belirlemeyi kolaylaştırır. |
| LLM'lere karşı bir 'prompt enjeksiyonu (prompt injection)' saldırısı nedir? | Kötü niyetli bir kullanıcının, LLM'yi amaçlanmayan şekillerde hareket etmesi için kandırmak amacıyla bir yönlendirme enjekte etmesidir. |
Yapay Zeka Uygulamalarının Perde Arkası: LangChain Kitabından 5 Şaşırtıcı Gerçek
Giriş: Yapay Zekanın "Sihrinin" Ardındaki Gerçekler
ChatGPT'nin 2022'deki lansmanıyla birlikte yapay zeka (AI), bir anda hayatlarımızın merkezine oturdu. İnsan gibi soruları anlayan, metinler üreten ve karmaşık problemleri çözen bu teknoloji, pek çoğumuza sihirli gibi göründü. Ancak yapay zeka ile bir şeyler inşa etmek veya bu alana yatırım yapmak isteyen herkes için, bu pürüzsüz kullanıcı deneyimi ile temelindeki mühendislik gerçeği arasındaki boşluğu anlamak hayati önem taşır. Bu makale, tam olarak bu boşluğu kapatıyor.
Bu "sihrin" arkasında yatan gerçekler, genellikle sanıldığından çok daha ilginç ve şaşırtıcıdır. O'Reilly'nin "Learning LangChain" kitabından yola çıkarak, Büyük Dil Modelleri (LLM'ler) ve onlarla modern uygulamalar geliştirmenin ardındaki en çarpıcı, ezber bozan ve etkili beş gerçeği açıklayacağız. Bu yazı, yapay zekanın sadece bir kullanıcısı olmaktan öteye geçip nasıl çalıştığını daha derinlemesine anlamak isteyenler için bir rehber niteliğindedir.
--------------------------------------------------------------------------------
1. LLM'ler Aslında Düşünmüyor, Sadece Kelime Tahmini Yapıyor
LLM'lerin insan gibi "düşündüğü" veya karmaşık metinleri "anladığı" yönündeki yaygın kanı, aslında büyüleyici bir yanılsamadır. Temelde çalışma prensipleri, akıllı telefonlarımızdaki otomatik tamamlama özelliğinin aşırı gelişmiş bir versiyonu olarak düşünülebilir. Bir LLM, kendisine verilen metin dizisine dayanarak bir sonraki en olası kelimenin ne olacağını istatistiksel olarak tahmin eder. Bilinçli bir akıl yürütme yerine, devasa veri setlerindeki kelime kalıplarını tanır.
Bu mekanizmayı somutlaştırmak için basit bir örnek düşünelim: "İngiltere'nin başkenti ______". Model, eğitim verilerinde "İngiltere", "başkent" ve "Londra" kelimelerinin milyonlarca kez bir arada geçtiğini "görmüştür". Bu nedenle, boşluğu doldurmak için en yüksek olasılığa sahip kelimenin "Londra" olduğunu tahmin eder. Bu, bir bilgiden veya anlayıştan değil, tamamen olasılık hesabından kaynaklanır.
En şaşırtıcı detaylardan biri ise LLM'lerin kelimelerle değil, "token" adı verilen metin birimleriyle çalışmasıdır. Tokenlar kelimeler, kelime parçaları ve hatta noktalama işaretleri olabilir. "Learning LangChain" kitabındaki bir örnekte, dearest kelimesi _de ve arest olarak iki token'a ayrılır. Bunun sebebi, tokenizer'ların en yaygın kelimeleri tek bir token'a kodlama hedefiyle eğitilmesidir. morning gibi çok yaygın bir kelime tek bir token olurken, daha az yaygın olan dearest gibi kelimeler birden fazla token gerektirir. Bu teknik, modelin daha önce görmediği veya nadir kullanılan kelimelerle başa çıkmasını sağlayarak dile karşı esnekliğini artırır.
--------------------------------------------------------------------------------
2. Devasa Zekalar, Basit Matematikte Sınıfta Kalıyor
Bir LLM'nin kuantum fiziği hakkında şiirler yazabilmesi, ancak cep hesap makinenizin on yıllar önce çözdüğü bir konuda tökezlemesi şaşırtıcıdır. LLM'lerin tahmine dayalı doğası, dilsel akıcılıklarını açıklarken, aynı zamanda şok edici bir zayıflık yaratır: temel matematik. Milyarlarca parametreye sahip bu devasa modeller, en temel aritmetik işlemlerinde bile şaşırtıcı derecede başarısız olabilir. Çünkü onlar birer dil modelidir; matematiksel mantık için tasarlanmamışlardır.
Bu temel sınırlılık, LangChain gibi çerçevelerin doğuşuna ilham vermiştir. LangChain'in kurucusu Harrison Chase'in fark ettiği üzere:
"...en ilginç LLM uygulamalarının, LLM'leri 'diğer hesaplama veya bilgi kaynakları' ile birlikte kullanması gerektiği fark edildi."
Kitaptaki "1.234 top, her biri 123 toptan oluşan gruplara ayrılırsa geriye kaç top kalır?" sorusu bu durumu mükemmel bir şekilde özetler. Modern bir yapay zeka uygulaması, bu soruyu doğrudan LLM'ye çözdürmeye çalışmaz. Bunun yerine LLM, soruyu bir hesap makinesi aracının anlayabileceği 1234 % 123 (modulo işlemi) formatına dönüştürmesi için yönlendirilir. Modelin bu "çeviri" yeteneği, LangChain gibi çerçevelerin temel gücünü oluşturur. Bu, modern yapay zeka uygulamalarının neden sadece bir LLM'den ibaret olmadığını gösteren en önemli derslerden biridir.
--------------------------------------------------------------------------------
3. Sadece Sormak Yetmez: "Adım Adım Düşün" Demenin Gücü
Bir LLM'den kaliteli bir sonuç almanın yolu, sadece doğru soruyu sormaktan geçmez. Soruyu nasıl sorduğumuz, yani "prompt mühendisliği", çıktının kalitesini dramatik bir şekilde etkileyebilir. Bazen tek bir sihirli ifade, modelin başarısız bir cevaptan parlak bir analize geçmesini sağlayabilir.
Kitaptaki "ABD'nin 30. başkanı..." ile ilgili soru bu durumu çarpıcı bir şekilde gösteriyor. Modelden bu bilgi "zero-shot" (yani doğrudan) istendiğinde, başkanın adını doğru verse de başka bir konuda tamamen yanılır: Başkan Coolidge’in eşinin annesi için yanlış doğum ve ölüm yıllarını listeler.
Ancak prompt'un başına eklenen tek bir sihirli cümle her şeyi değiştirir: "Adım Adım Düşün" (Think step by step). Bu basit talimat eklendiğinde, model artık doğrudan bir cevap vermek yerine, doğru cevaba ulaşmak için izlenmesi gereken mantıksal adımları sıralamaya başlar:
- Önce 30. başkanın kim olduğunu bul.
- Sonra ilgili kişilerin doğum ve ölüm tarihlerini araştır.
- Son olarak, bu tarihler arasında hesaplama yap.
Bu basit ifade, modelin içsel "düşünme" sürecini tetikleyerek daha karmaşık görevlerdeki performansını ve güvenilirliğini önemli ölçüde artırır. Bu, LLM'lerle etkileşim kurarken kullanılabilecek en şaşırtıcı ve pratik ipuçlarından biridir. Ancak en iyi prompt bile modelin bilmediği bir şeyi ona öğretemez. Bu da bizi bir sonraki şaşırtıcı gerçeğe getiriyor.
--------------------------------------------------------------------------------
4. LLM'lerin Hafızası Sınırlı: Bilgi Kesintisi ve RAG Çözümü
Her şeyi bilen bir kahin gibi görünseler de, LLM'lerin hafızası şaşırtıcı derecede kırılgandır ve iki büyük kör noktası vardır. Bu modeller her şeyi bilen varlıklar değildir ve iki temel sınırlılıkları bulunur:
- Özel Verilere Erişememe: Şirketinizin iç dokümanları veya kişisel e-postalarınız gibi halka açık olmayan bilgilere sahip değillerdir.
- Bilgi Kesintisi (Knowledge Cutoff): Eğitim verilerinin toplandığı tarihten sonraki olayları bilmezler. Örneğin, 2023'te eğitilmiş bir model 2024'te olan olaylar hakkında hiçbir şey bilemez.
Bu sorunu çözmek için kullanılan temel tekniğin adı Retrieval-Augmented Generation (RAG)'dır. RAG'ı en basit haliyle şöyle tanımlayabiliriz: "LLM'ye bir soru sormadan önce ona konuyla ilgili belgeleri vererek 'açık kitap sınavı' yapmasını sağlamak." Bu yaklaşım, LLM'nin soruyu yanıtlarken hem güncel hem de özel bilgilere erişmesini sağlar. Bu teknik, LLM'leri güncel ve özel bilgilerle güçlendirir ve "kendi verilerinizle sohbet etme" yeteneğine sahip kurumsal uygulamaların temelini oluşturur.
--------------------------------------------------------------------------------
5. Otonomi mi, Güvenilirlik mi? Yapay Zeka Geliştirmenin Temel İkilemi
Her güçlü yapay zeka uygulamasının kalbinde, geliştiricinin çözmesi gereken temel bir felsefi ikilem yatar: sisteme ne kadar özgürlük verilmeli ve ne kadar kontrol sağlanmalı? Bu, otonomi (agency) ve güvenilirlik (reliability) arasındaki denge olarak ifade edilir.
- Otonomi, bir yapay zekanın insan müdahalesi olmadan ne kadar çok ve karmaşık eylemde bulunabildiği anlamına gelir. Örneğin, sizin adınıza e-postalara otomatik olarak yanıt vermesi yüksek otonomi göstergesidir.
- Güvenilirlik ise bu eylemlerin sonuçlarına ne kadar güvenebileceğimizle ilgilidir.
Bu iki kavram arasında doğal bir ödünleşim (trade-off) vardır. Kitaptaki e-posta asistanı örneğini düşünelim: Asistan ne kadar otonom olursa (ne kadar çok e-postayı kendi başına yanıtlarsa) o kadar faydalı olur. Ancak bu durum, göndermesini asla istemeyeceğiniz hatalı veya uygunsuz bir e-postayı gönderme riskini de o kadar artırır.
Bu otonomi ve güvenilirlik arasındaki temel denge, önceki tüm gerçekleri değerlendirmemiz gereken stratejik bir mercektir. Bir LLM'nin matematik yapamaması (Gerçek 2) veya sınırlı hafızası (Gerçek 4), geliştiricilerin özel araçlarla "Chain" mimarileri oluşturarak çözdüğü güvenilirlik sorunlarıdır; bu sırada LLM'nin otonomisini kasıtlı olarak sınırlarlar. Öte yandan, "Agent" mimarileri daha yüksek otonomi sunarken, öngörülemezlikleri nedeniyle güvenilirlikleri daha düşüktür. Bu dengeyi doğru kurmak, bir geliştiricinin yapay zeka uygulaması tasarlarken vermesi gereken en kritik kararlardan biridir.
--------------------------------------------------------------------------------
Sonuç: Sihirden Mimariye
Bu beş gerçeği öğrendikten sonra, yapay zekanın büyülü perdesinin ardında aslında ne kadar mantıklı ve yapılandırılmış bir dünya olduğu ortaya çıkıyor. LLM'ler sihirli değildir; onlar güçlü, ancak belirli sınırlılıkları olan araçlardır.
- Onlar düşünmez, sadece istatistiksel olarak tahmin yapar.
- Tek başlarına yetersizdirler ve hesap makinesi gibi harici araçlara ihtiyaç duyarlar.
- Onlara "nasıl düşüneceklerini" söylemek, yani doğru prompt mühendisliği, sonuçları kökten değiştirir.
- Hafızaları sınırlıdır ve güncel/özel bilgiler için RAG gibi tekniklere bağımlıdırlar.
- Geliştirme süreci, otonomi ve güvenilirlik arasında hassas bir denge kurma sanatıdır.
Bu gerçekler sadece ilginç teknik detaylar değil, aynı zamanda modern yapay zeka geliştiricilerinin neden birer sihirbazdan çok mimara benzediğinin de kanıtıdır. Onların işi, tek bir monolitik "beyin" yaratmak değil; LLM'leri bir tür "dil işlemci" olarak kullanarak, onları hesap makineleri, veritabanları ve arama motorları gibi diğer özel bileşenlerle birleştiren sağlam bir mimari inşa etmektir.
Bu yapı taşlarını öğrendiğinize göre, bir Büyük Dil Modelini doğru araçlar ve verilerle birleştirerek hangi 'imkansız' görünen problemi çözmek isterdiniz?